 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLobsDICE: Offline Imitation Learning from Observation via Stationary Distribution Correction Estimation
Paper and Code
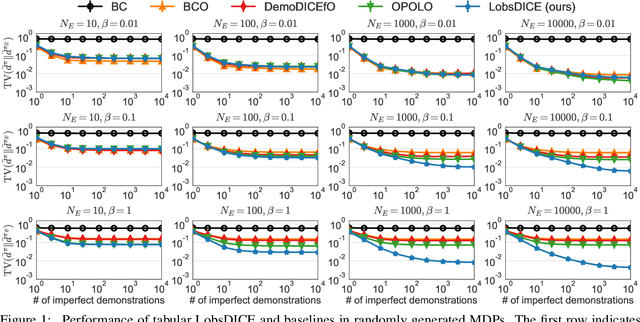
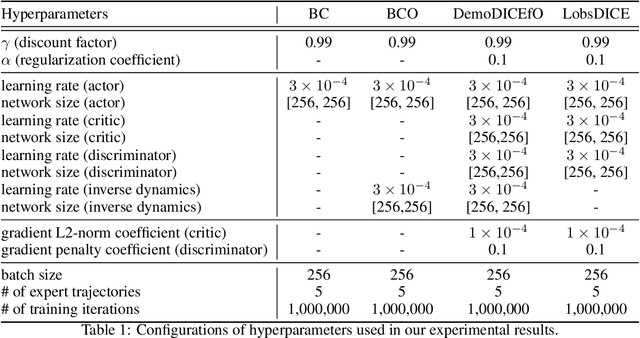

We consider the problem of imitation from observation (IfO), in which the agent aims to mimic the expert's behavior from the state-only demonstrations by experts. We additionally assume that the agent cannot interact with the environment but has access to the action-labeled transition data collected by some agent with unknown quality. This offline setting for IfO is appealing in many real-world scenarios where the ground-truth expert actions are inaccessible and the arbitrary environment interactions are costly or risky. In this paper, we present LobsDICE, an offline IfO algorithm that learns to imitate the expert policy via optimization in the space of stationary distributions. Our algorithm solves a single convex minimization problem, which minimizes the divergence between the two state-transition distributions induced by the expert and the agent policy. On an extensive set of offline IfO tasks, LobsDICE shows promising results, outperforming strong baseline algorithms.