 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM4LV: A Frozen Large Language Model for Low-level Vision Tasks
Paper and Code

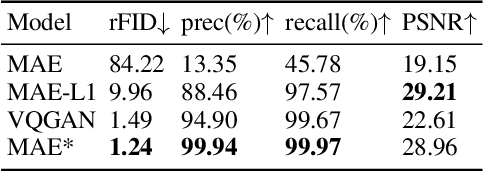
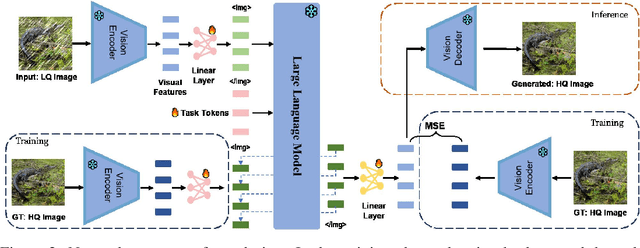
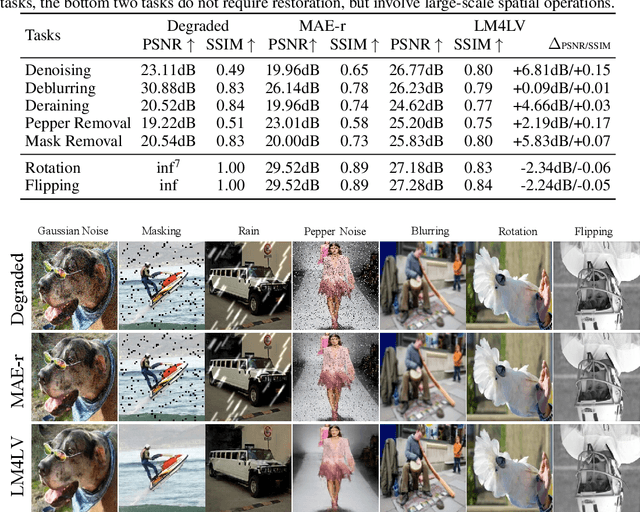
The success of large language models (LLMs) has fostered a new research trend of multi-modality large language models (MLLMs), which changes the paradigm of various fields in computer vision. Though MLLMs have shown promising results in numerous high-level vision and vision-language tasks such as VQA and text-to-image, no works have demonstrated how low-level vision tasks can benefit from MLLMs. We find that most current MLLMs are blind to low-level features due to their design of vision modules, thus are inherently incapable for solving low-level vision tasks. In this work, we purpose $\textbf{LM4LV}$, a framework that enables a FROZEN LLM to solve a range of low-level vision tasks without any multi-modal data or prior. This showcases the LLM's strong potential in low-level vision and bridges the gap between MLLMs and low-level vision tasks. We hope this work can inspire new perspectives on LLMs and deeper understanding of their mechanisms.