 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLITO: Learnable Intervention for Truthfulness Optimization
Paper and Code
May 01, 2024
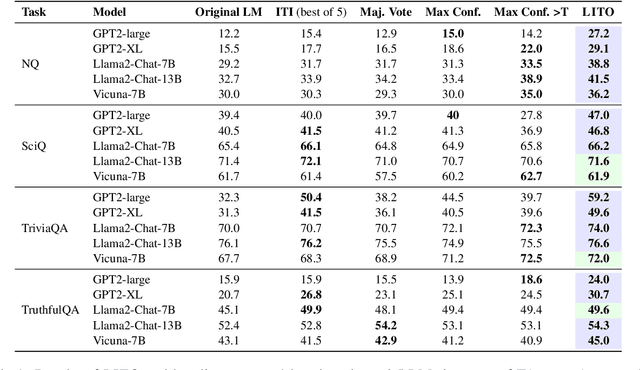

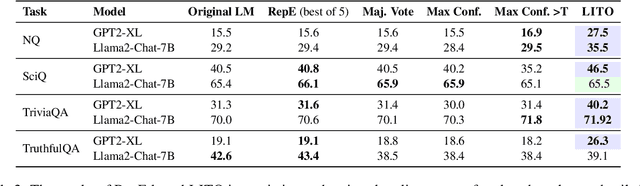
Large language models (LLMs) can generate long-form and coherent text, but they still frequently hallucinate facts, thus limiting their reliability. To address this issue, inference-time methods that elicit truthful responses have been proposed by shifting LLM representations towards learned "truthful directions". However, applying the truthful directions with the same intensity fails to generalize across different question contexts. We propose LITO, a Learnable Intervention method for Truthfulness Optimization that automatically identifies the optimal intervention intensity tailored to a specific context. LITO explores a sequence of model generations based on increasing levels of intervention intensities. It selects the most accurate response or refuses to answer when the predictions are highly uncertain. Experiments on multiple LLMs and question-answering datasets demonstrate that LITO improves truthfulness while preserving task accuracy. The adaptive nature of LITO counters issues with one-size-fits-all intervention-based solutions, maximizing model truthfulness by reflecting internal knowledge only when the model is confident.