 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLip-to-Speech Synthesis in the Wild with Multi-task Learning
Paper and Code
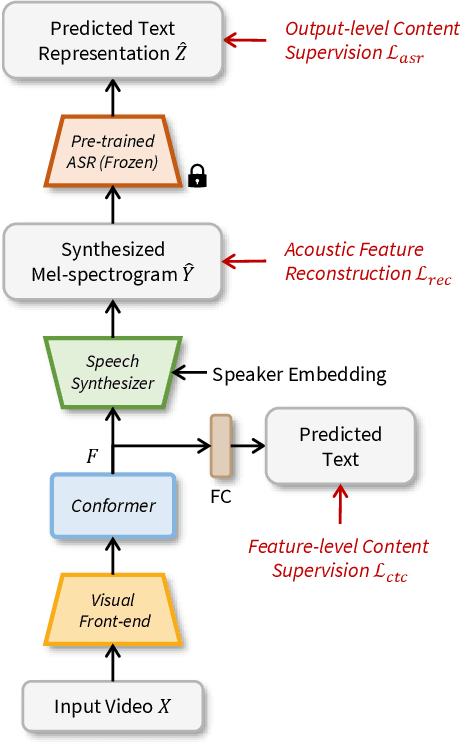
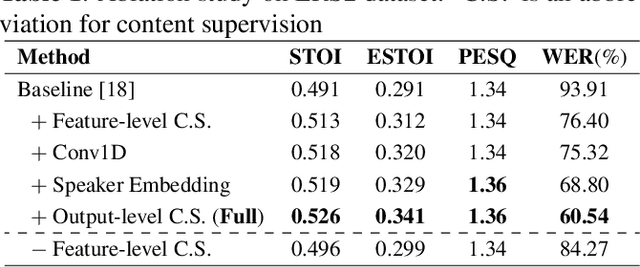
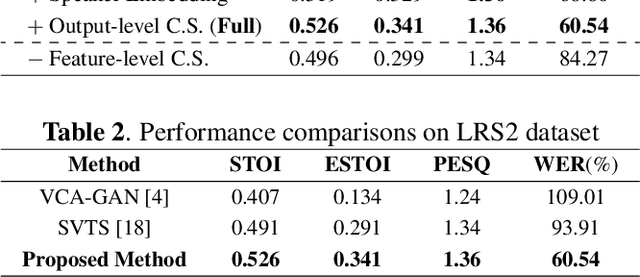
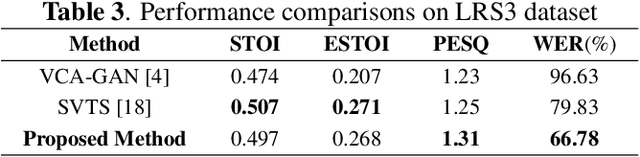
Recent studies have shown impressive performance in Lip-to-speech synthesis that aims to reconstruct speech from visual information alone. However, they have been suffering from synthesizing accurate speech in the wild, due to insufficient supervision for guiding the model to infer the correct content. Distinct from the previous methods, in this paper, we develop a powerful Lip2Speech method that can reconstruct speech with correct contents from the input lip movements, even in a wild environment. To this end, we design multi-task learning that guides the model using multimodal supervision, i.e., text and audio, to complement the insufficient word representations of acoustic feature reconstruction loss. Thus, the proposed framework brings the advantage of synthesizing speech containing the right content of multiple speakers with unconstrained sentences. We verify the effectiveness of the proposed method using LRS2, LRS3, and LRW datasets.