 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Laws Meet Protein Sequences: A Comparative Analysis of Subword Tokenization Methods
Paper and Code
Nov 26, 2024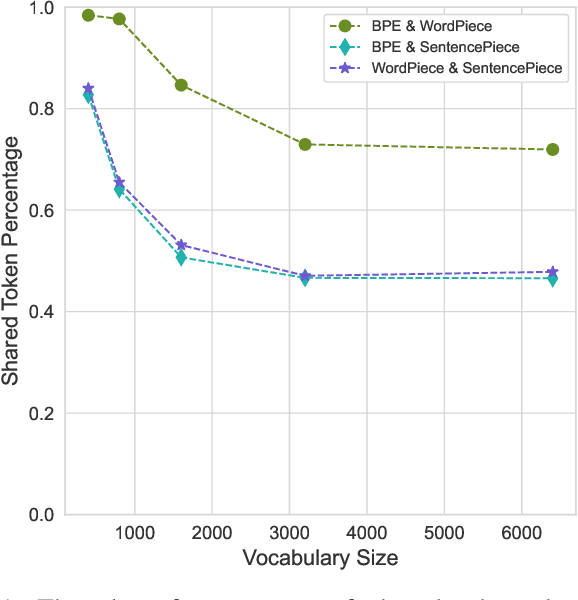
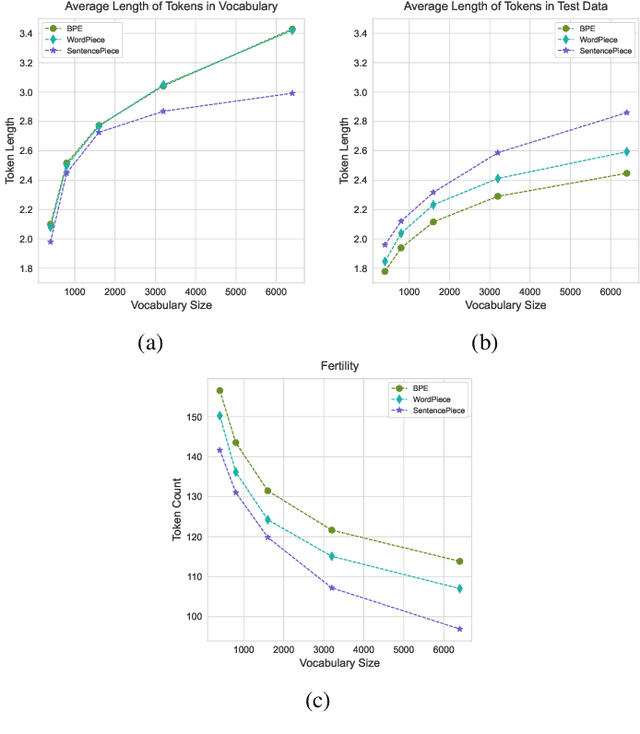
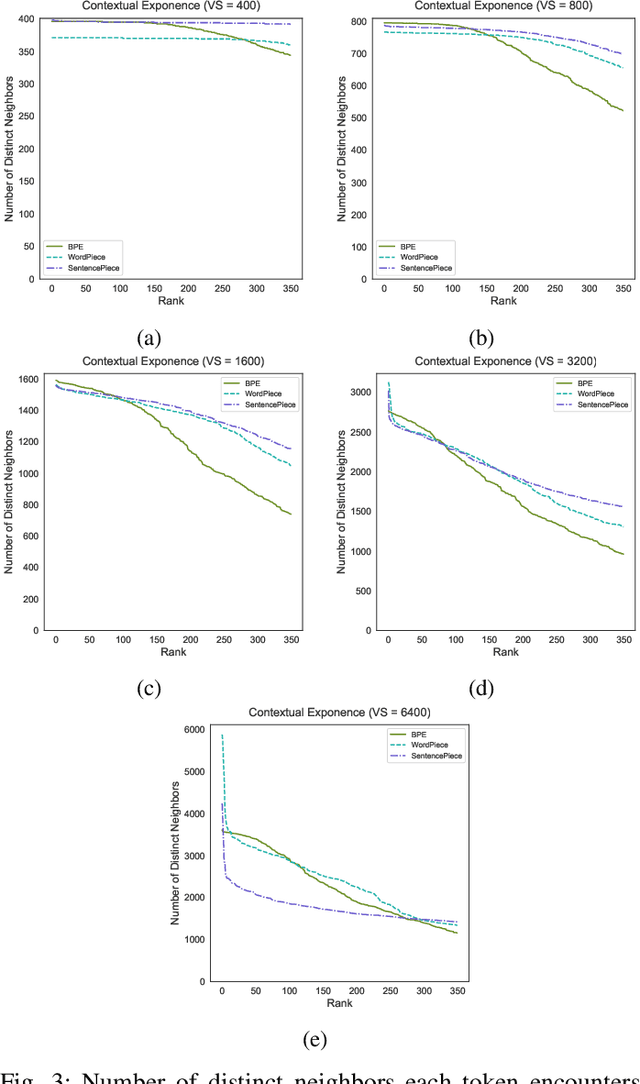
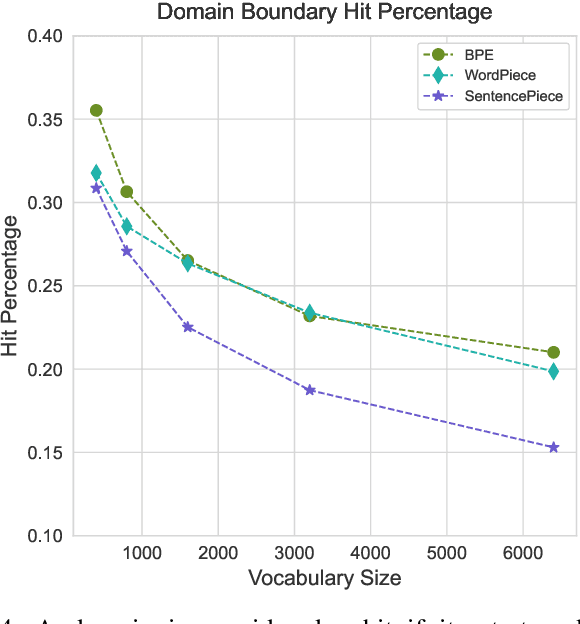
Tokenization is a crucial step in processing protein sequences for machine learning models, as proteins are complex sequences of amino acids that require meaningful segmentation to capture their functional and structural properties. However, existing subword tokenization methods, developed primarily for human language, may be inadequate for protein sequences, which have unique patterns and constraints. This study evaluates three prominent tokenization approaches, Byte-Pair Encoding (BPE), WordPiece, and SentencePiece, across varying vocabulary sizes (400-6400), analyzing their effectiveness in protein sequence representation, domain boundary preservation, and adherence to established linguistic laws. Our comprehensive analysis reveals distinct behavioral patterns among these tokenizers, with vocabulary size significantly influencing their performance. BPE demonstrates better contextual specialization and marginally better domain boundary preservation at smaller vocabularies, while SentencePiece achieves better encoding efficiency, leading to lower fertility scores. WordPiece offers a balanced compromise between these characteristics. However, all tokenizers show limitations in maintaining protein domain integrity, particularly as vocabulary size increases. Analysis of linguistic law adherence shows partial compliance with Zipf's and Brevity laws but notable deviations from Menzerath's law, suggesting that protein sequences may follow distinct organizational principles from natural languages. These findings highlight the limitations of applying traditional NLP tokenization methods to protein sequences and emphasize the need for developing specialized tokenization strategies that better account for the unique characteristics of proteins.