 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Tensor Projection Revealing Nonlinearity
Paper and Code
Jul 08, 2020


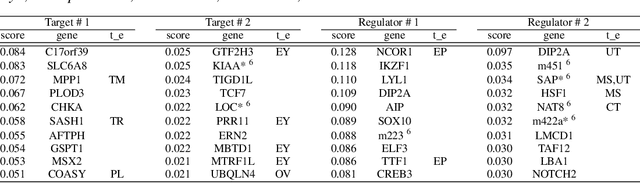
Dimensionality reduction is an effective method for learning high-dimensional data, which can provide better understanding of decision boundaries in human-readable low-dimensional subspace. Linear methods, such as principal component analysis and linear discriminant analysis, make it possible to capture the correlation between many variables; however, there is no guarantee that the correlations that are important in predicting data can be captured. Moreover, if the decision boundary has strong nonlinearity, the guarantee becomes increasingly difficult. This problem is exacerbated when the data are matrices or tensors that represent relationships between variables. We propose a learning method that searches for a subspace that maximizes the prediction accuracy while retaining as much of the original data information as possible, even if the prediction model in the subspace has strong nonlinearity. This makes it easier to interpret the mechanism of the group of variables behind the prediction problem that the user wants to know. We show the effectiveness of our method by applying it to various types of data including matrices and tensors.