 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Convergence of Adaptive Stochastic Gradient Descent
Paper and Code

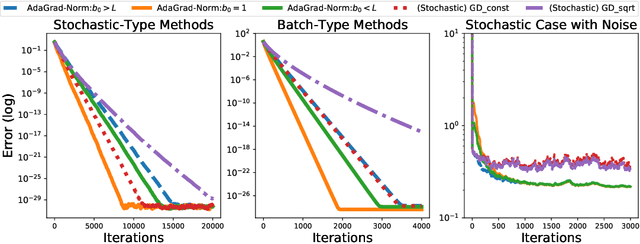
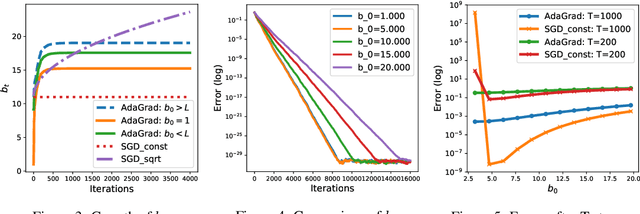
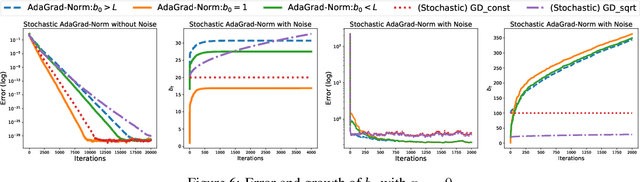
We prove that the norm version of the adaptive stochastic gradient method (AdaGrad-Norm) achieves a linear convergence rate for a subset of either strongly convex functions or non-convex functions that satisfy the Polyak-Lojasiewicz (PL) inequality. The paper introduces the notion of Restricted Uniform Inequality of Gradients (RUIG), which describes the uniform lower bound for the norm of the stochastic gradients with respect to the distance to the optimal solution. RUIG plays the key role in proving the robustness of AdaGrad-Norm to its hyper-parameter tuning. On top of RUIG, we develop a novel two-stage framework to prove linear convergence of AdaGrad-Norm without knowing the parameters of the objective functions: Stage I: the step-size decrease fast such that it reaches to Stage II; Stage II: the step-size decreases slowly and converges. This framework can likely be extended to other adaptive stepsize algorithms. The numerical experiments show desirable agreement with our theories.