 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations and Alternatives for the Evaluation of Large-scale Link Prediction
Paper and Code
Nov 25, 2016
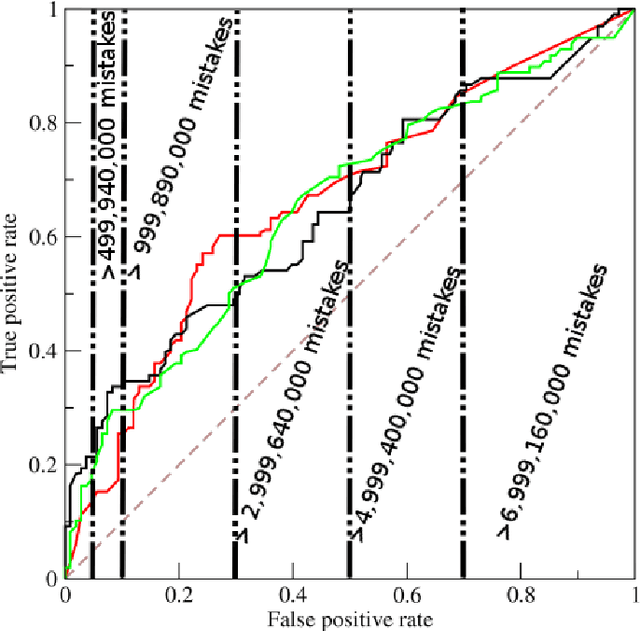
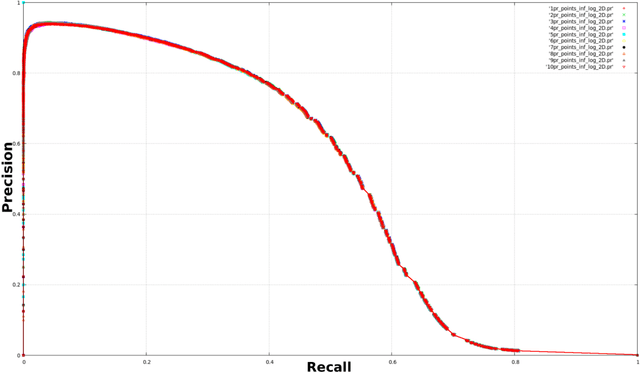
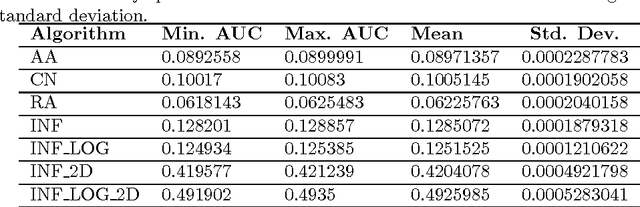
Link prediction, the problem of identifying missing links among a set of inter-related data entities, is a popular field of research due to its application to graph-like domains. Producing consistent evaluations of the performance of the many link prediction algorithms being proposed can be challenging due to variable graph properties, such as size and density. In this paper we first discuss traditional data mining solutions which are applicable to link prediction evaluation, arguing about their capacity for producing faithful and useful evaluations. We also introduce an innovative modification to a traditional evaluation methodology with the goal of adapting it to the problem of evaluating link prediction algorithms when applied to large graphs, by tackling the problem of class imbalance. We empirically evaluate the proposed methodology and, building on these findings, make a case for its importance on the evaluation of large-scale graph processing.