 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood Assignment for Out-of-Distribution Inputs in Deep Generative Models is Sensitive to Prior Distribution Choice
Paper and Code
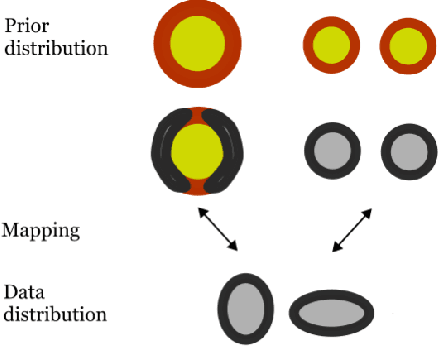
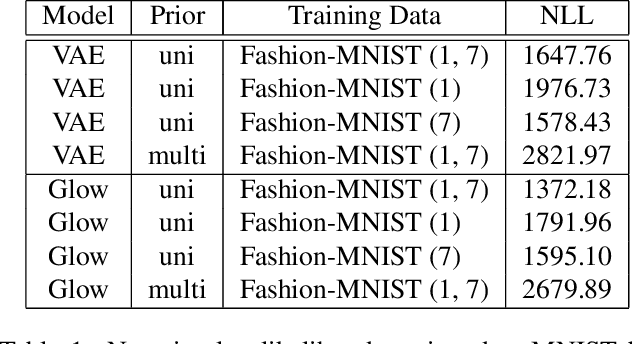
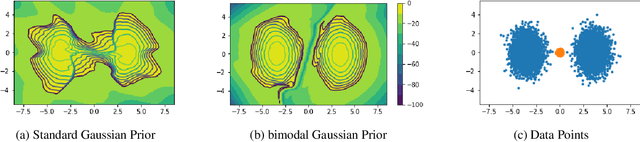

Recent work has shown that deep generative models assign higher likelihood to out-of-distribution inputs than to training data. We show that a factor underlying this phenomenon is a mismatch between the nature of the prior distribution and that of the data distribution, a problem found in widely used deep generative models such as VAEs and Glow. While a typical choice for a prior distribution is a standard Gaussian distribution, properties of distributions of real data sets may not be consistent with a unimodal prior distribution. This paper focuses on the relationship between the choice of a prior distribution and the likelihoods assigned to out-of-distribution inputs. We propose the use of a mixture distribution as a prior to make likelihoods assigned by deep generative models sensitive to out-of-distribution inputs. Furthermore, we explain the theoretical advantages of adopting a mixture distribution as the prior, and we present experimental results to support our claims. Finally, we demonstrate that a mixture prior lowers the out-of-distribution likelihood with respect to two pairs of real image data sets: Fashion-MNIST vs. MNIST and CIFAR10 vs. SVHN.