 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Residual Densely Connected Convolutional Neural Network
Paper and Code
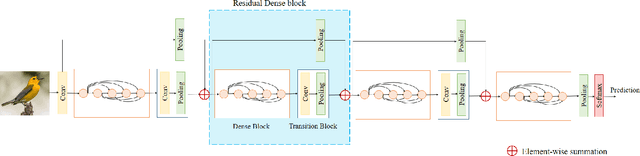


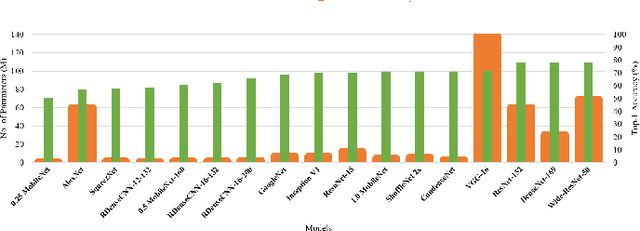
Extremely efficient convolutional neural network architectures are one of the most important requirements for limited computing power devices (such as embedded and mobile devices). Recently, some architectures have been proposed to overcome this limitation by considering specific hardware-software equipment. In this paper, the residual densely connected blocks are proposed to guaranty the deep supervision, efficient gradient flow, and feature reuse abilities of convolutional neural network. The proposed method decreases the cost of training and inference processes without using any special hardware-software equipment by just reducing the number of parameters and computational operations while achieving a feasible accuracy. Extensive experimental results demonstrate that the proposed architecture is more efficient than the AlexNet and VGGNet in terms of model size, required parameters, and even accuracy. The proposed model is evaluated on the ImageNet, MNIST, Fashion MNIST, SVHN, CIFAR-10, and CIFAR-100. It achieves state-of-the-art results on the Fashion MNIST dataset and reasonable results on the others. The obtained results show that the proposed model is superior to efficient models such as the SqueezNet and is also comparable with the state-of-the-art efficient models such as CondenseNet and ShuffleNet.