 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Weight RetinaNet for Object Detection
Paper and Code
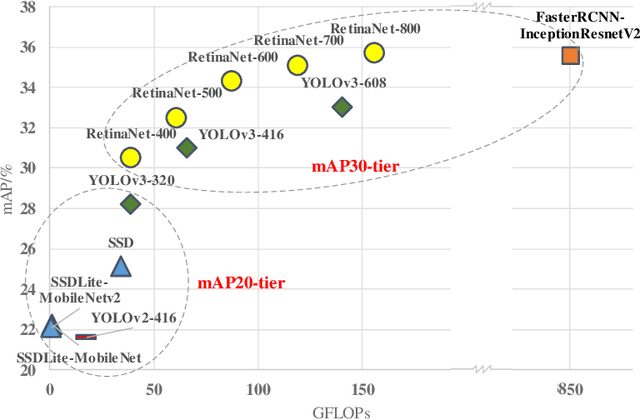



Object detection has gained great progress driven by the development of deep learning. Compared with a widely studied task -- classification, generally speaking, object detection even need one or two orders of magnitude more FLOPs (floating point operations) in processing the inference task. To enable a practical application, it is essential to explore effective runtime and accuracy trade-off scheme. Recently, a growing number of studies are intended for object detection on resource constraint devices, such as YOLOv1, YOLOv2, SSD, MobileNetv2-SSDLite, whose accuracy on COCO test-dev detection results are yield to mAP around 22-25% (mAP-20-tier). On the contrary, very few studies discuss the computation and accuracy trade-off scheme for mAP-30-tier detection networks. In this paper, we illustrate the insights of why RetinaNet gives effective computation and accuracy trade-off for object detection and how to build a light-weight RetinaNet. We propose to only reduce FLOPs in computational intensive layers and keep other layer the same. Compared with most common way -- input image scaling for FLOPs-accuracy trade-off, the proposed solution shows a constantly better FLOPs-mAP trade-off line. Quantitatively, the proposed method result in 0.1% mAP improvement at 1.15x FLOPs reduction and 0.3% mAP improvement at 1.8x FLOPs reduction.