 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifted Bregman Training of Neural Networks
Paper and Code
Aug 18, 2022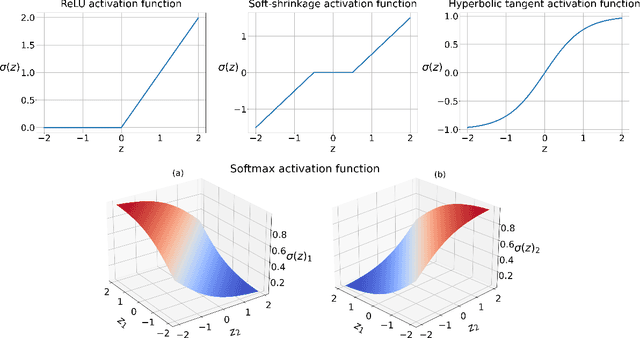



We introduce a novel mathematical formulation for the training of feed-forward neural networks with (potentially non-smooth) proximal maps as activation functions. This formulation is based on Bregman distances and a key advantage is that its partial derivatives with respect to the network's parameters do not require the computation of derivatives of the network's activation functions. Instead of estimating the parameters with a combination of first-order optimisation method and back-propagation (as is the state-of-the-art), we propose the use of non-smooth first-order optimisation methods that exploit the specific structure of the novel formulation. We present several numerical results that demonstrate that these training approaches can be equally well or even better suited for the training of neural network-based classifiers and (denoising) autoencoders with sparse coding compared to more conventional training frameworks.