 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeViT-UNet: Make Faster Encoders with Transformer for Medical Image Segmentation
Paper and Code
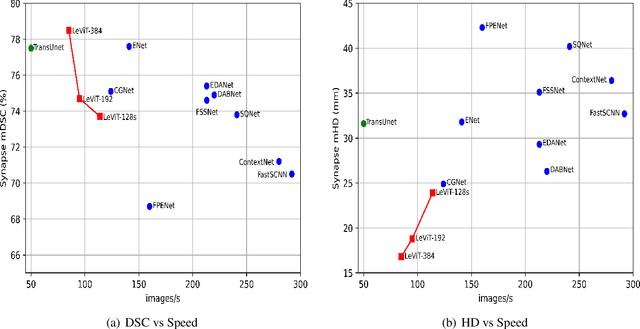
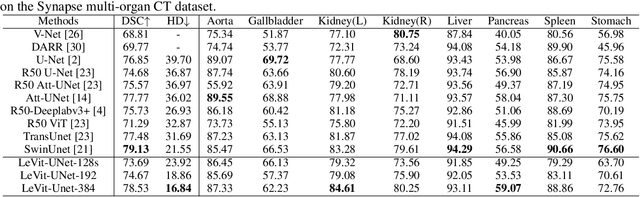
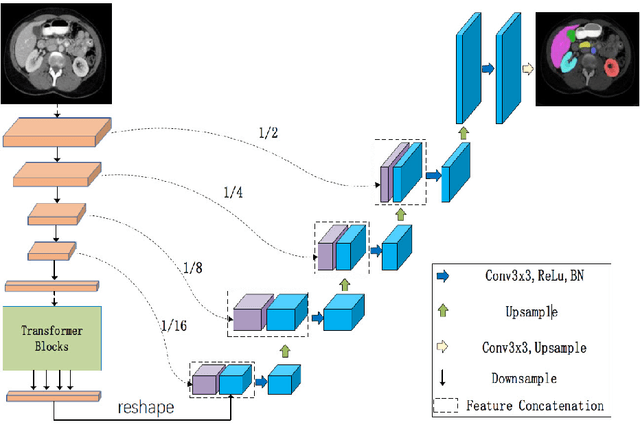
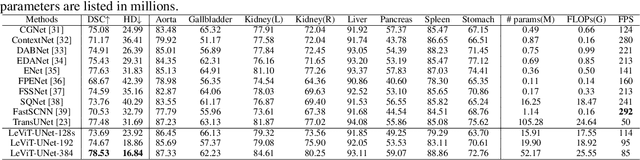
Medical image segmentation plays an essential role in developing computer-assisted diagnosis and therapy systems, yet still faces many challenges. In the past few years, the popular encoder-decoder architectures based on CNNs (e.g., U-Net) have been successfully applied in the task of medical image segmentation. However, due to the locality of convolution operations, they demonstrate limitations in learning global context and long-range spatial relations. Recently, several researchers try to introduce transformers to both the encoder and decoder components with promising results, but the efficiency requires further improvement due to the high computational complexity of transformers. In this paper, we propose LeViT-UNet, which integrates a LeViT Transformer module into the U-Net architecture, for fast and accurate medical image segmentation. Specifically, we use LeViT as the encoder of the LeViT-UNet, which better trades off the accuracy and efficiency of the Transformer block. Moreover, multi-scale feature maps from transformer blocks and convolutional blocks of LeViT are passed into the decoder via skip-connection, which can effectively reuse the spatial information of the feature maps. Our experiments indicate that the proposed LeViT-UNet achieves better performance comparing to various competing methods on several challenging medical image segmentation benchmarks including Synapse and ACDC. Code and models will be publicly available at https://github.com/apple1986/LeViT_UNet.