 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength-Adaptive Transformer: Train Once with Length Drop, Use Anytime with Search
Paper and Code

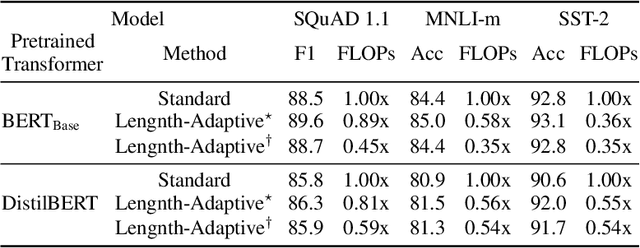

Although transformers have achieved impressive accuracies in various tasks in natural language processing, they often come with a prohibitive computational cost, that prevents their use in scenarios with limited computational resources for inference. This need for computational efficiency in inference has been addressed by for instance PoWER-BERT (Goyal et al., 2020) which gradually decreases the length of a sequence as it is passed through layers. These approaches however often assume that the target computational complexity is known in advance at the time of training. This implies that a separate model must be trained for each inference scenario with its distinct computational budget. In this paper, we extend PoWER-BERT to address this issue of inefficiency and redundancy. The proposed extension enables us to train a large-scale transformer, called Length-Adaptive Transformer, once and uses it for various inference scenarios without re-training it. To do so, we train a transformer with LengthDrop, a structural variant of dropout, which stochastically determines the length of a sequence at each layer. We then use a multi-objective evolutionary search to find a length configuration that maximizes the accuracy and minimizes the computational complexity under any given computational budget. Additionally, we significantly extend the applicability of PoWER-BERT beyond sequence-level classification into token-level classification such as span-based question-answering, by introducing the idea of Drop-and-Restore. With Drop-and-Restore, word-vectors are dropped temporarily in intermediate layers and restored at the last layer if necessary. We empirically verify the utility of the proposed approach by demonstrating the superior accuracy-efficiency trade-off under various setups, including SQuAD 1.1, MNLI-m, and SST-2. Code is available at https://github.com/clovaai/length-adaptive-transformer.