 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnware: Small Models Do Big
Paper and Code
Oct 07, 2022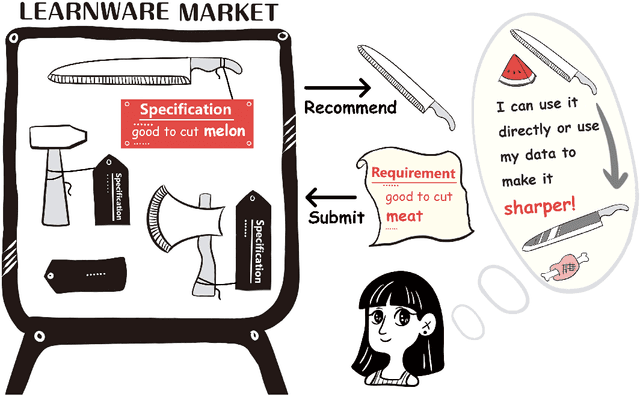
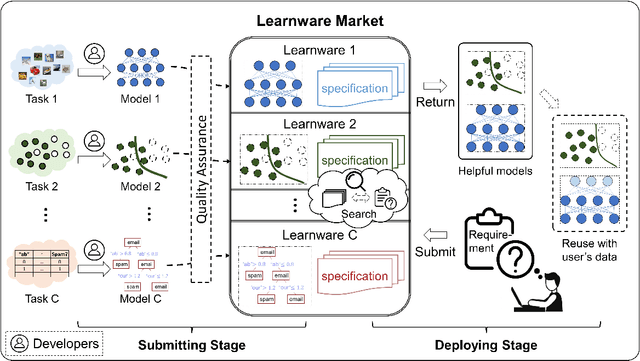
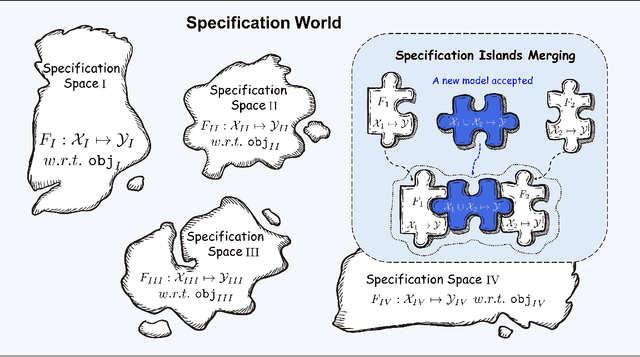
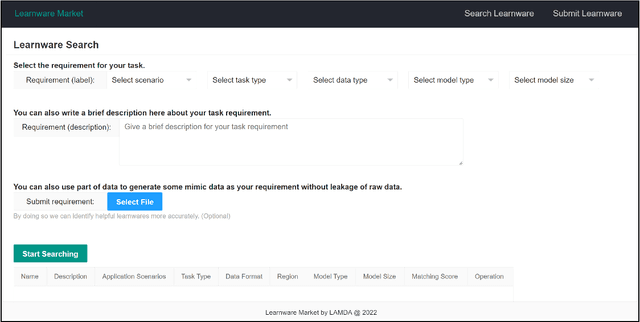
There are complaints about current machine learning techniques such as the requirement of a huge amount of training data and proficient training skills, the difficulty of continual learning, the risk of catastrophic forgetting, the leaking of data privacy/proprietary, etc. Most research efforts have been focusing on one of those concerned issues separately, paying less attention to the fact that most issues are entangled in practice. The prevailing big model paradigm, which has achieved impressive results in natural language processing and computer vision applications, has not yet addressed those issues, whereas becoming a serious source of carbon emissions. This article offers an overview of the learnware paradigm, which attempts to enable users not need to build machine learning models from scratch, with the hope of reusing small models to do things even beyond their original purposes, where the key ingredient is the specification which enables a trained model to be adequately identified to reuse according to the requirement of future users who know nothing about the model in advance.