 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning utterance-level representations through token-level acoustic latents prediction for Expressive Speech Synthesis
Paper and Code
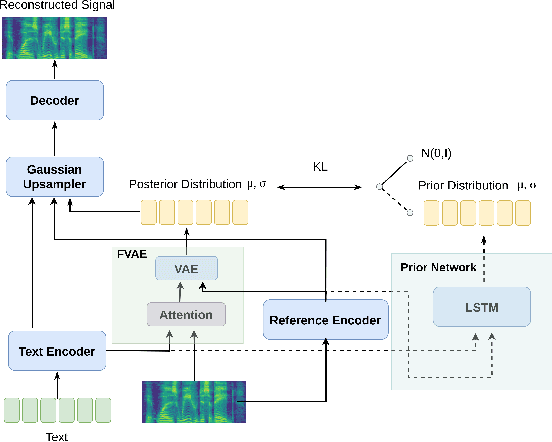
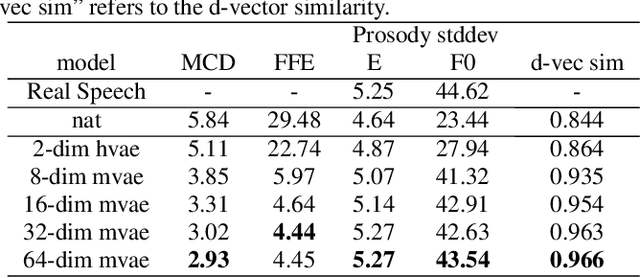
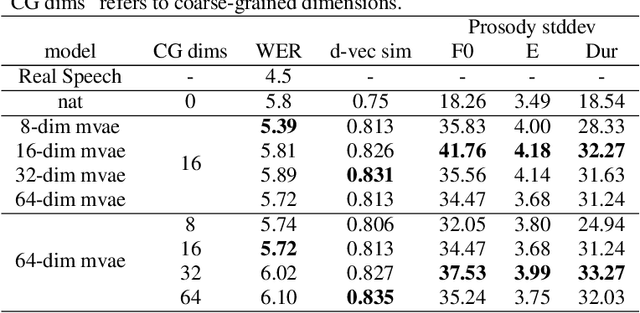
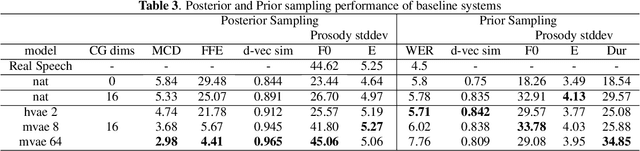
This paper proposes an Expressive Speech Synthesis model that utilizes token-level latent prosodic variables in order to capture and control utterance-level attributes, such as character acting voice and speaking style. Current works aim to explicitly factorize such fine-grained and utterance-level speech attributes into different representations extracted by modules that operate in the corresponding level. We show that the fine-grained latent space also captures coarse-grained information, which is more evident as the dimension of latent space increases in order to capture diverse prosodic representations. Therefore, a trade-off arises between the diversity of the token-level and utterance-level representations and their disentanglement. We alleviate this issue by first capturing rich speech attributes into a token-level latent space and then, separately train a prior network that given the input text, learns utterance-level representations in order to predict the phoneme-level, posterior latents extracted during the previous step. Both qualitative and quantitative evaluations are used to demonstrate the effectiveness of the proposed approach. Audio samples are available in our demo page.