 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Sample Replacements for ELECTRA Pre-Training
Paper and Code



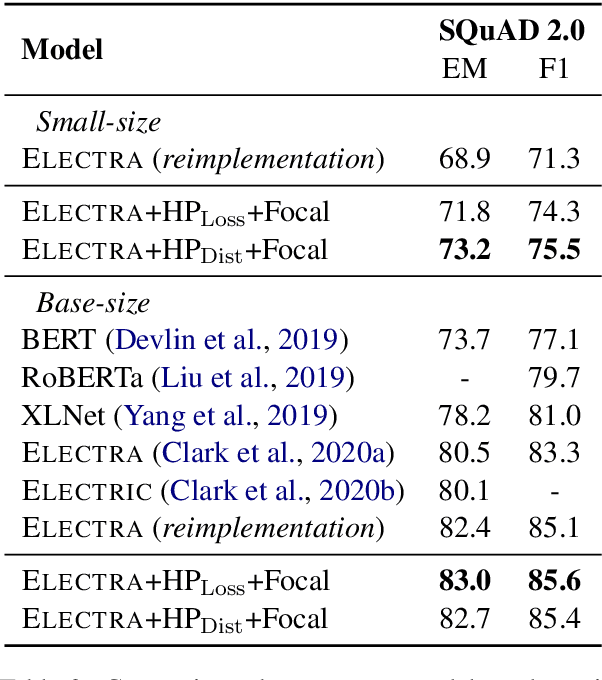
ELECTRA pretrains a discriminator to detect replaced tokens, where the replacements are sampled from a generator trained with masked language modeling. Despite the compelling performance, ELECTRA suffers from the following two issues. First, there is no direct feedback loop from discriminator to generator, which renders replacement sampling inefficient. Second, the generator's prediction tends to be over-confident along with training, making replacements biased to correct tokens. In this paper, we propose two methods to improve replacement sampling for ELECTRA pre-training. Specifically, we augment sampling with a hardness prediction mechanism, so that the generator can encourage the discriminator to learn what it has not acquired. We also prove that efficient sampling reduces the training variance of the discriminator. Moreover, we propose to use a focal loss for the generator in order to relieve oversampling of correct tokens as replacements. Experimental results show that our method improves ELECTRA pre-training on various downstream tasks.