 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rectify for Robust Learning with Noisy Labels
Paper and Code
Nov 08, 2021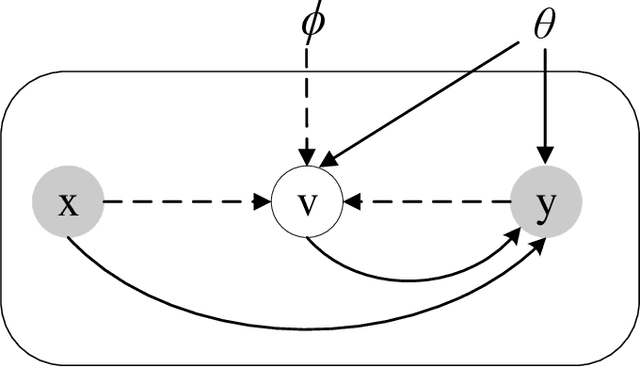
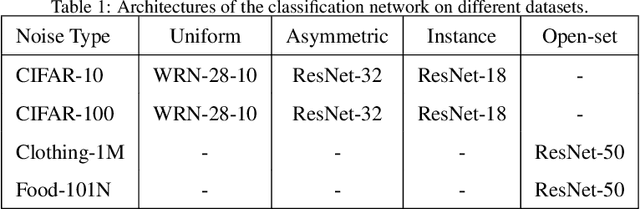
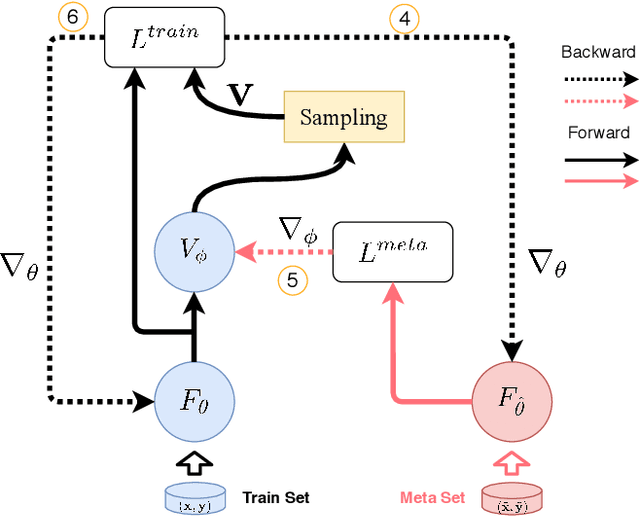
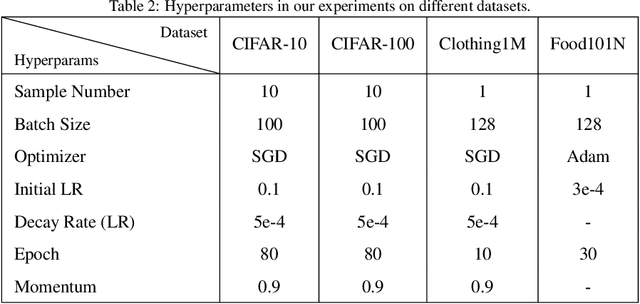
Label noise significantly degrades the generalization ability of deep models in applications. Effective strategies and approaches, \textit{e.g.} re-weighting, or loss correction, are designed to alleviate the negative impact of label noise when training a neural network. Those existing works usually rely on the pre-specified architecture and manually tuning the additional hyper-parameters. In this paper, we propose warped probabilistic inference (WarPI) to achieve adaptively rectifying the training procedure for the classification network within the meta-learning scenario. In contrast to the deterministic models, WarPI is formulated as a hierarchical probabilistic model by learning an amortization meta-network, which can resolve sample ambiguity and be therefore more robust to serious label noise. Unlike the existing approximated weighting function of directly generating weight values from losses, our meta-network is learned to estimate a rectifying vector from the input of the logits and labels, which has the capability of leveraging sufficient information lying in them. This provides an effective way to rectify the learning procedure for the classification network, demonstrating a significant improvement of the generalization ability. Besides, modeling the rectifying vector as a latent variable and learning the meta-network can be seamlessly integrated into the SGD optimization of the classification network. We evaluate WarPI on four benchmarks of robust learning with noisy labels and achieve the new state-of-the-art under variant noise types. Extensive study and analysis also demonstrate the effectiveness of our model.