 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank from Relevance Judgments Distributions
Paper and Code
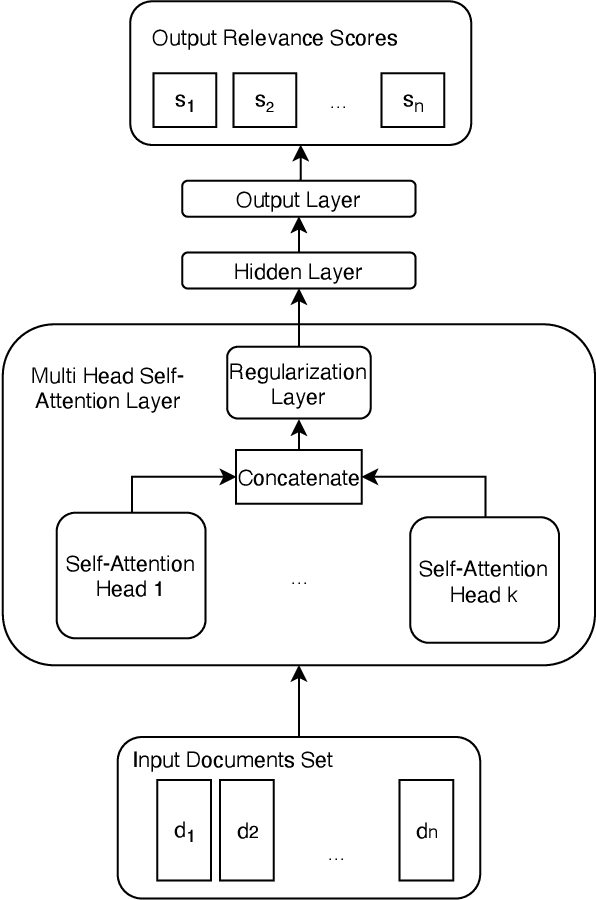
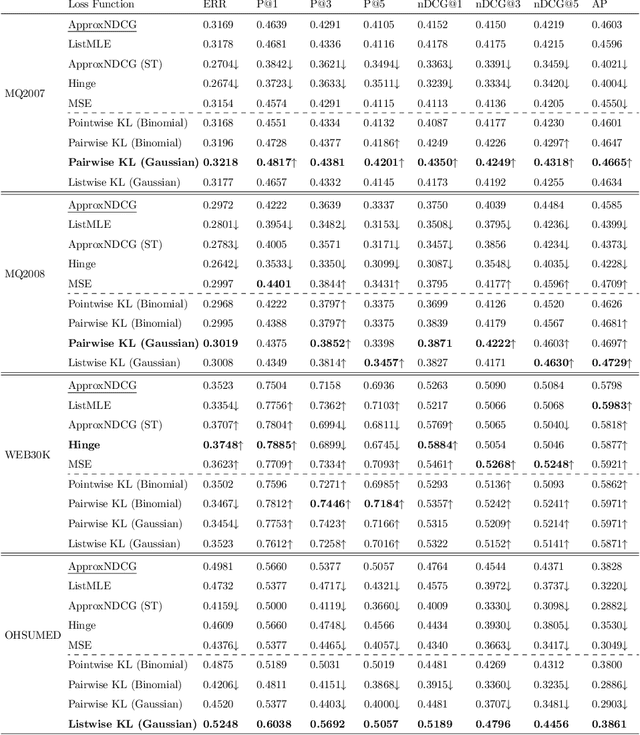
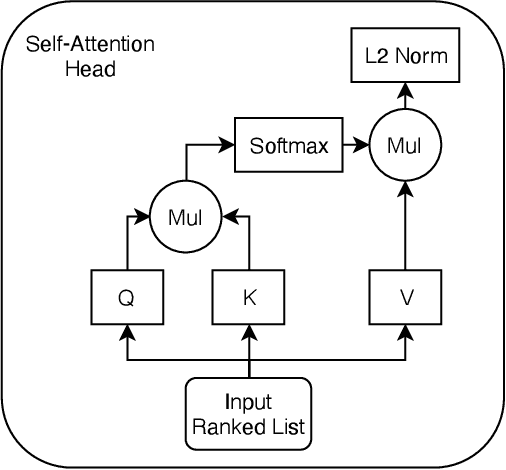
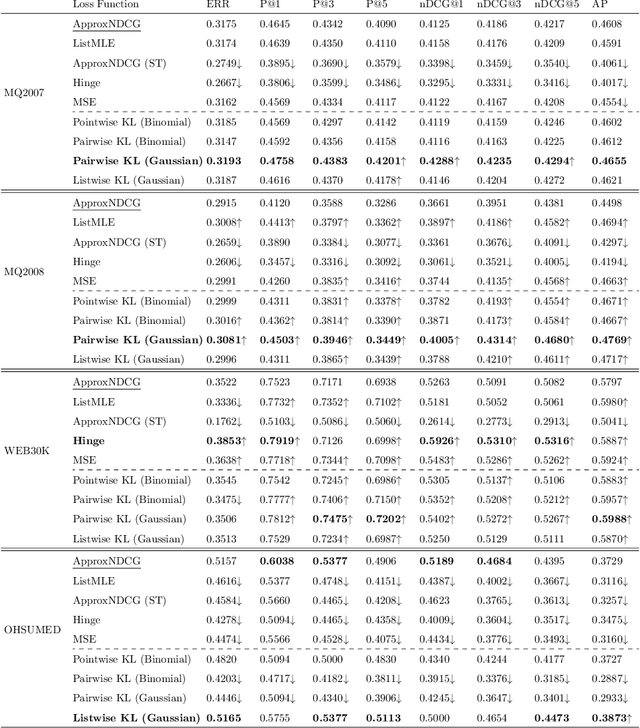
Learning to Rank (LETOR) algorithms are usually trained on annotated corpora where a single relevance label is assigned to each available document-topic pair. Within the Cranfield framework, relevance labels result from merging either multiple expertly curated or crowdsourced human assessments. In this paper, we explore how to train LETOR models with relevance judgments distributions (either real or synthetically generated) assigned to document-topic pairs instead of single-valued relevance labels. We propose five new probabilistic loss functions to deal with the higher expressive power provided by relevance judgments distributions and show how they can be applied both to neural and GBM architectures. Moreover, we show how training a LETOR model on a sampled version of the relevance judgments from certain probability distributions can improve its performance when relying either on traditional or probabilistic loss functions. Finally, we validate our hypothesis on real-world crowdsourced relevance judgments distributions. Overall, we observe that relying on relevance judgments distributions to train different LETOR models can boost their performance and even outperform strong baselines such as LambdaMART on several test collections.