 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Locate Visual Answer in Video Corpus Using Question
Paper and Code
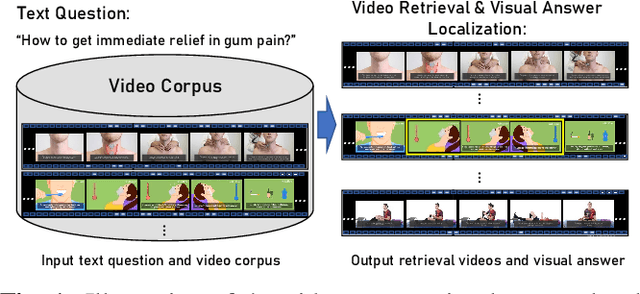
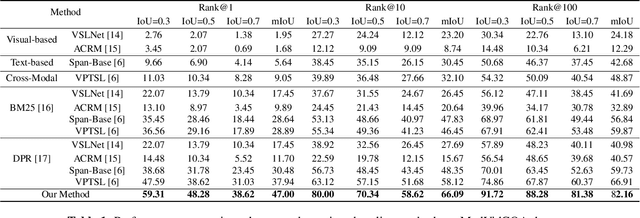
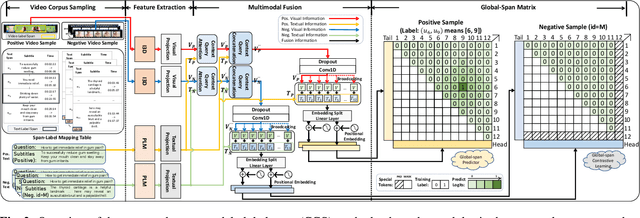

We introduce a novel task, named video corpus visual answer localization (VCVAL), which aims to locate the visual answer in a large collection of untrimmed, unsegmented instructional videos using a natural language question. This task requires a range of skills - the interaction between vision and language, video retrieval, passage comprehension, and visual answer localization. To solve these, we propose a cross-modal contrastive global-span (CCGS) method for the VCVAL, jointly training the video corpus retrieval and visual answer localization tasks. More precisely, we enhance the video question-answer semantic by adding element-wise visual information into the pre-trained language model, and designing a novel global-span predictor through fusion information to locate the visual answer point. The Global-span contrastive learning is adopted to differentiate the span point in the positive and negative samples with the global-span matrix. We have reconstructed a new dataset named MedVidCQA and benchmarked the VCVAL task, where the proposed method achieves state-of-the-art (SOTA) both in the video corpus retrieval and visual answer localization tasks. Most importantly, we pave a new path for understanding the instructional videos, performing detailed analyses on extensive experiments, which ushers in further research.