 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Imagine: Visually-Augmented Natural Language Generation
Paper and Code
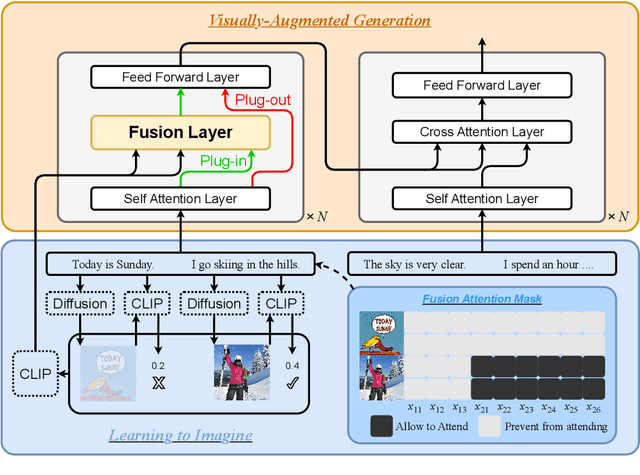
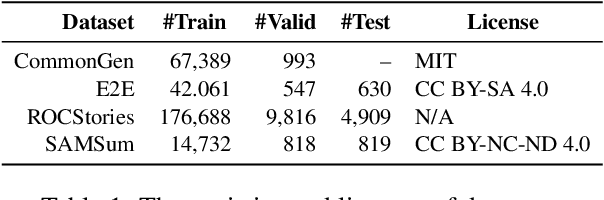
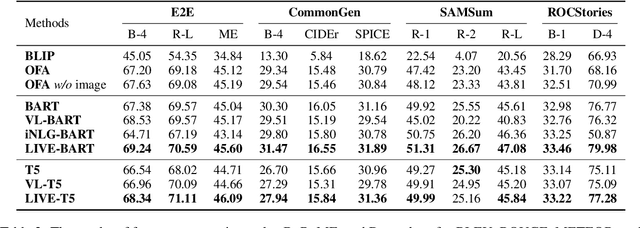
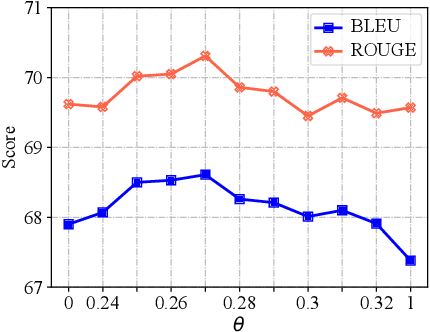
People often imagine relevant scenes to aid in the writing process. In this work, we aim to utilize visual information for composition in the same manner as humans. We propose a method, LIVE, that makes pre-trained language models (PLMs) Learn to Imagine for Visuallyaugmented natural language gEneration. First, we imagine the scene based on the text: we use a diffusion model to synthesize high-quality images conditioned on the input texts. Second, we use CLIP to determine whether the text can evoke the imagination in a posterior way. Finally, our imagination is dynamic, and we conduct synthesis for each sentence rather than generate only one image for an entire paragraph. Technically, we propose a novel plug-and-play fusion layer to obtain visually-augmented representations for each text. Our vision-text fusion layer is compatible with Transformerbased architecture. We have conducted extensive experiments on four generation tasks using BART and T5, and the automatic results and human evaluation demonstrate the effectiveness of our proposed method. We will release the code, model, and data at the link: https://github.com/RUCAIBox/LIVE.