 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation
Paper and Code
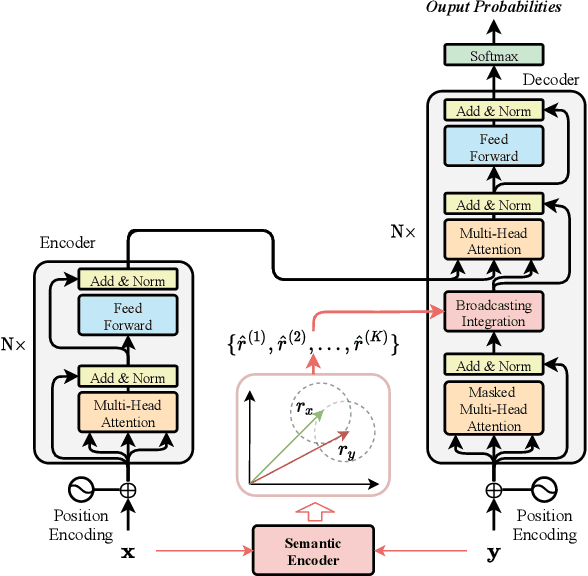
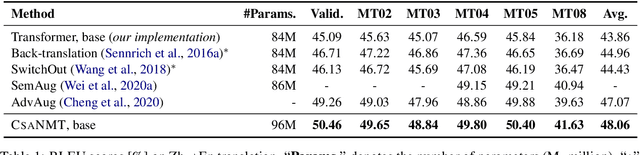
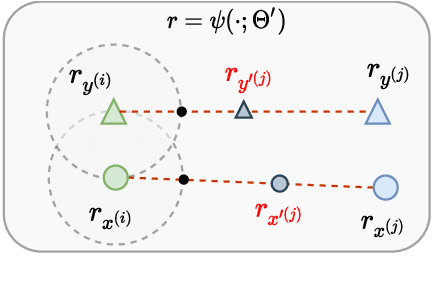
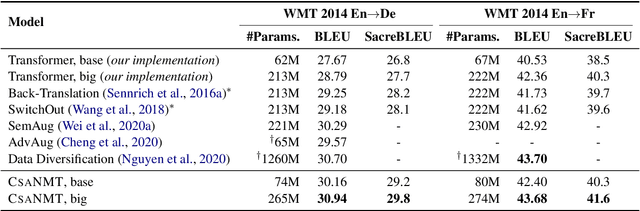
The principal task in supervised neural machine translation (NMT) is to learn to generate target sentences conditioned on the source inputs from a set of parallel sentence pairs, and thus produce a model capable of generalizing to unseen instances. However, it is commonly observed that the generalization performance of the model is highly influenced by the amount of parallel data used in training. Although data augmentation is widely used to enrich the training data, conventional methods with discrete manipulations fail to generate diverse and faithful training samples. In this paper, we present a novel data augmentation paradigm termed Continuous Semantic Augmentation (CsaNMT), which augments each training instance with an adjacency semantic region that could cover adequate variants of literal expression under the same meaning. We conduct extensive experiments on both rich-resource and low-resource settings involving various language pairs, including WMT14 English-{German,French}, NIST Chinese-English and multiple low-resource IWSLT translation tasks. The provided empirical evidences show that CsaNMT sets a new level of performance among existing augmentation techniques, improving on the state-of-the-art by a large margin. The core codes are contained in Appendix E.