 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Caption Images with Two-Stream Attention and Sentence Auto-Encoder
Paper and Code
Nov 22, 2019


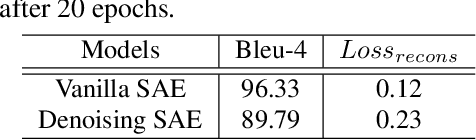
Automatically generating natural language descriptions from an image is a challenging problem in artificial intelligence that requires a good understanding of the correlations between visual and textual cues. To bridge these two modalities, state-of-the-art methods commonly use a dynamic interface between image and text, called attention, that learns to identify related image parts to estimate the next word conditioned on the previous steps. While this mechanism is effective, it fails to find the right associations between visual and textual cues when they are noisy. In this paper we propose two novel approaches to address this issue - (i) a two-stream attention mechanism that can automatically discover latent categories and relate them to image regions based on the previously generated words, (ii) a regularization technique that encapsulates the syntactic and semantic structure of captions and improves the optimization of the image captioning model. Our qualitative and quantitative results demonstrate remarkable improvements on the MSCOCO dataset setting and lead to new state-of-the-art performances for image captioning.