 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Representations Incrementally in Deep Reinforcement Learning
Paper and Code
Dec 09, 2019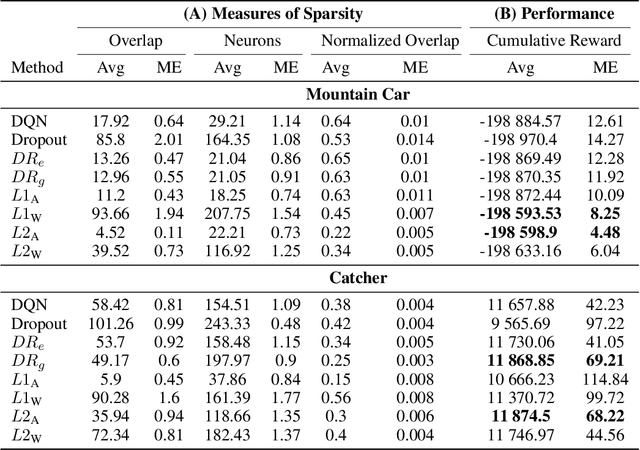
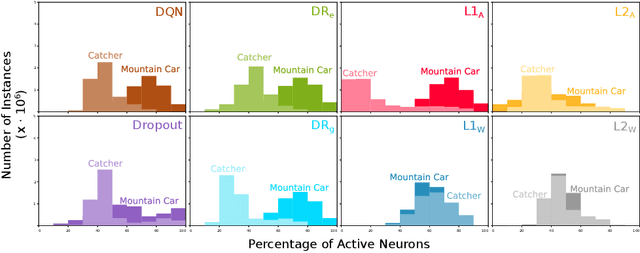
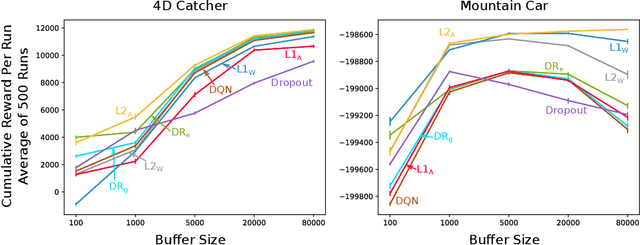
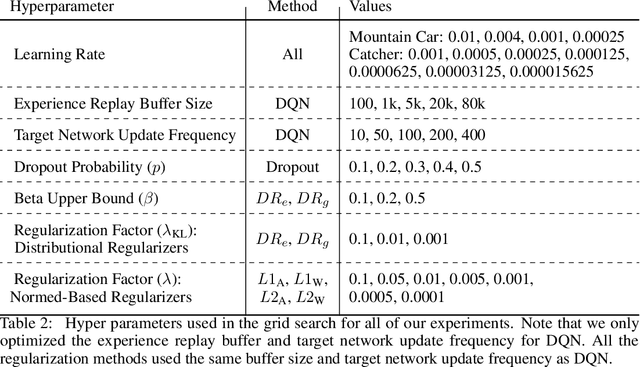
Sparse representations have been shown to be useful in deep reinforcement learning for mitigating catastrophic interference and improving the performance of agents in terms of cumulative reward. Previous results were based on a two step process were the representation was learned offline and the action-value function was learned online afterwards. In this paper, we investigate if it is possible to learn a sparse representation and the action-value function simultaneously and incrementally. We investigate this question by employing several regularization techniques and observing how they affect sparsity of the representation learned by a DQN agent in two different benchmark domains. Our results show that with appropriate regularization it is possible to increase the sparsity of the representations learned by DQN agents. Moreover, we found that learning sparse representations also resulted in improved performance in terms of cumulative reward. Finally, we found that the performance of the agents that learned a sparse representation was more robust to the size of the experience replay buffer. This last finding supports the long standing hypothesis that the overlap in representations learned by deep neural networks is the leading cause of catastrophic interference.