 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Routines for Effective Off-Policy Reinforcement Learning
Paper and Code
Jun 05, 2021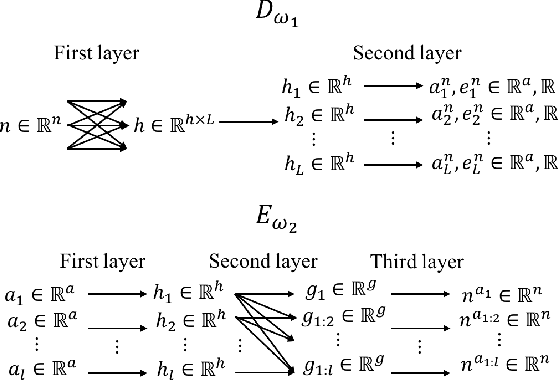
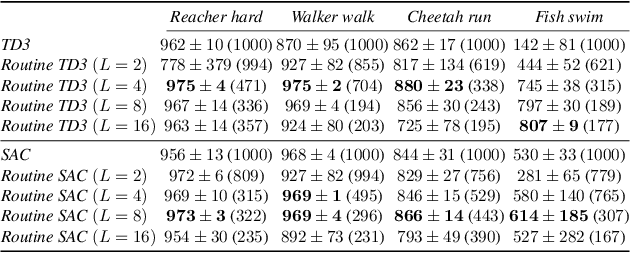


The performance of reinforcement learning depends upon designing an appropriate action space, where the effect of each action is measurable, yet, granular enough to permit flexible behavior. So far, this process involved non-trivial user choices in terms of the available actions and their execution frequency. We propose a novel framework for reinforcement learning that effectively lifts such constraints. Within our framework, agents learn effective behavior over a routine space: a new, higher-level action space, where each routine represents a set of 'equivalent' sequences of granular actions with arbitrary length. Our routine space is learned end-to-end to facilitate the accomplishment of underlying off-policy reinforcement learning objectives. We apply our framework to two state-of-the-art off-policy algorithms and show that the resulting agents obtain relevant performance improvements while requiring fewer interactions with the environment per episode, improving computational efficiency.