Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Revenue-Maximizing Auctions With Differentiable Matching
Paper and Code
Jun 15, 2021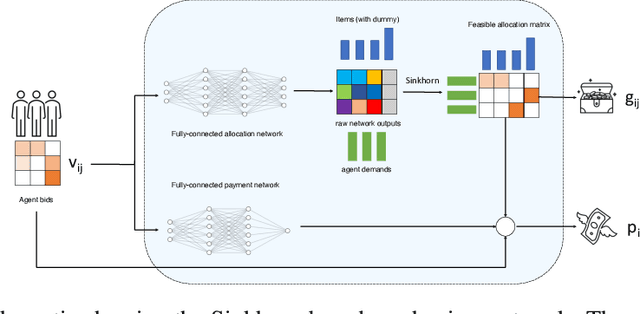

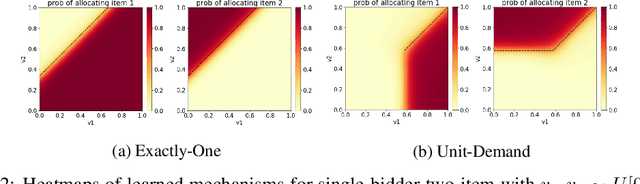
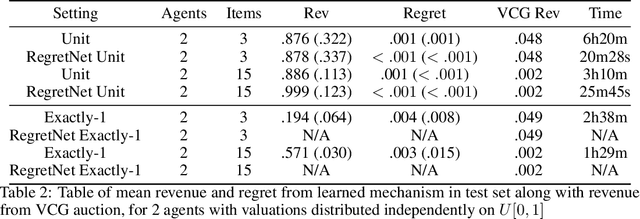
We propose a new architecture to approximately learn incentive compatible, revenue-maximizing auctions from sampled valuations. Our architecture uses the Sinkhorn algorithm to perform a differentiable bipartite matching which allows the network to learn strategyproof revenue-maximizing mechanisms in settings not learnable by the previous RegretNet architecture. In particular, our architecture is able to learn mechanisms in settings without free disposal where each bidder must be allocated exactly some number of items. In experiments, we show our approach successfully recovers multiple known optimal mechanisms and high-revenue, low-regret mechanisms in larger settings where the optimal mechanism is unknown.
View paper on