 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pessimism for Robust and Efficient Off-Policy Reinforcement Learning
Paper and Code
Oct 07, 2021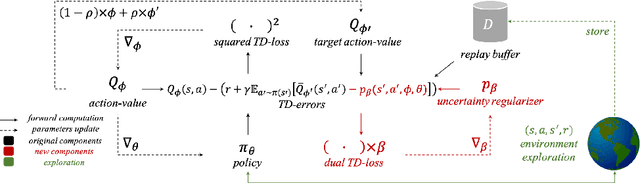



Popular off-policy deep reinforcement learning algorithms compensate for overestimation bias during temporal-difference learning by utilizing pessimistic estimates of the expected target returns. In this work, we propose a novel learnable penalty to enact such pessimism, based on a new way to quantify the critic's epistemic uncertainty. Furthermore, we propose to learn the penalty alongside the critic with dual TD-learning, a strategy to estimate and minimize the bias magnitude in the target returns. Our method enables us to accurately counteract overestimation bias throughout training without incurring the downsides of overly pessimistic targets. Empirically, by integrating our method and other orthogonal improvements with popular off-policy algorithms, we achieve state-of-the-art results in continuous control tasks from both proprioceptive and pixel observations.