 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Performance Graphs from Demonstrations via Task-Based Evaluations
Paper and Code
Apr 12, 2022
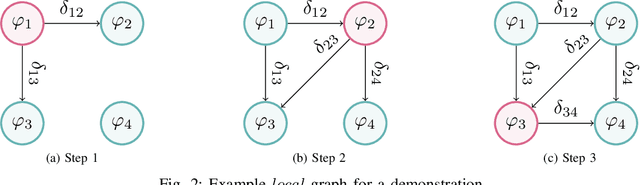

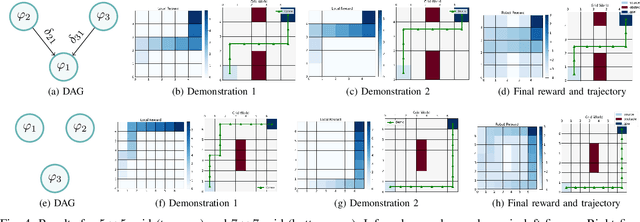
In the learning from demonstration (LfD) paradigm, understanding and evaluating the demonstrated behaviors plays a critical role in extracting control policies for robots. Without this knowledge, a robot may infer incorrect reward functions that lead to undesirable or unsafe control policies. Recent work has proposed an LfD framework where a user provides a set of formal task specifications to guide LfD, to address the challenge of reward shaping. However, in this framework, specifications are manually ordered in a performance graph (a partial order that specifies relative importance between the specifications). The main contribution of this paper is an algorithm to learn the performance graph directly from the user-provided demonstrations, and show that the reward functions generated using the learned performance graph generate similar policies to those from manually specified performance graphs. We perform a user study that shows that priorities specified by users on behaviors in a simulated highway driving domain match the automatically inferred performance graph. This establishes that we can accurately evaluate user demonstrations with respect to task specifications without expert criteria.