 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning over inherently distributed data
Paper and Code
Jul 30, 2019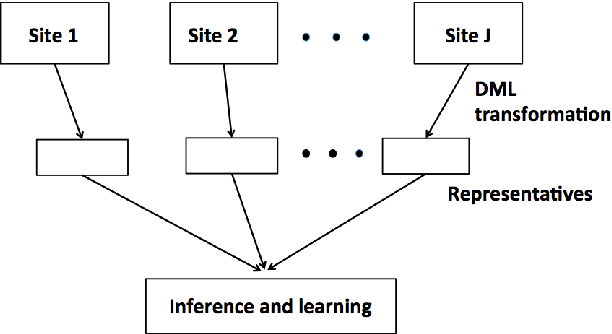
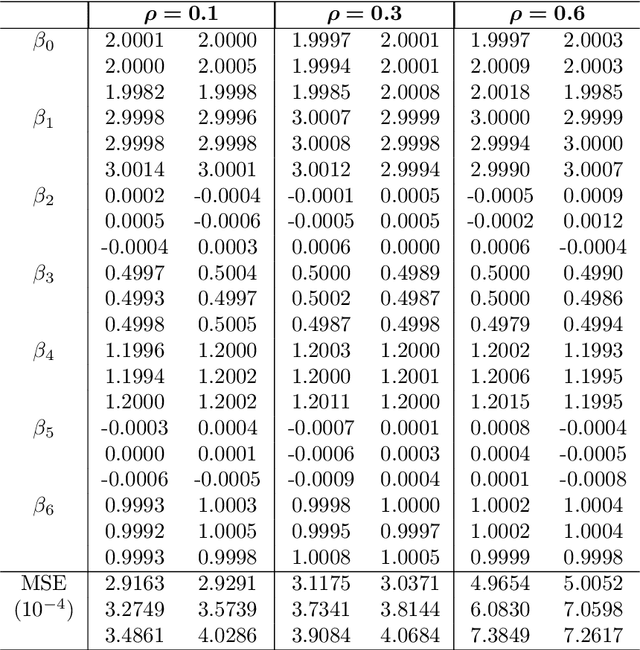
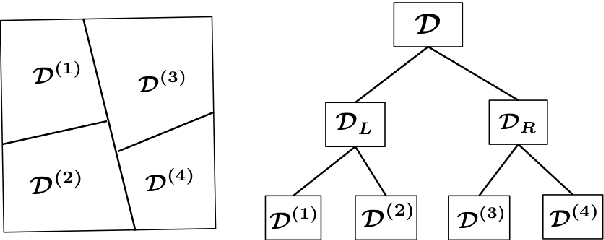

The recent decades have seen a surge of interests in distributed computing. Existing work focus primarily on either distributed computing platforms, data query tools, or, algorithms to divide big data and conquer at individual machines etc. It is, however, increasingly often that the data of interest are inherently distributed, i.e., data are stored at multiple distributed sites due to diverse collection channels, business operations etc. We propose to enable learning and inference in such a setting via a general framework based on the distortion minimizing local transformations. This framework only requires a small amount of local signatures to be shared among distributed sites, eliminating the need of having to transmitting big data. Computation can be done very efficiently via parallel local computation. The error incurred due to distributed computing vanishes when increasing the size of local signatures. As the shared data need not be in their original form, data privacy may also be preserved. Experiments on linear (logistic) regression and Random Forests have shown promise of this approach. This framework is expected to apply to a general class of tools in learning and inference with the continuity property.