 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Manipulation Skills from Video via Approximate Differentiable Physics
Paper and Code
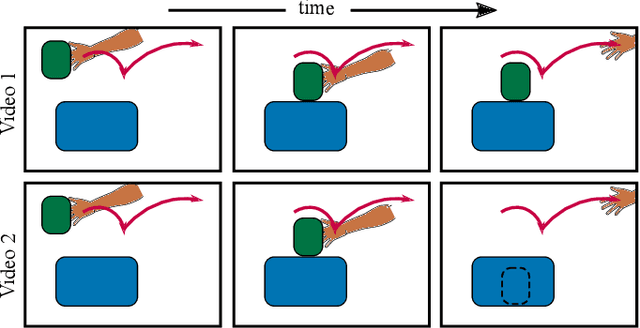
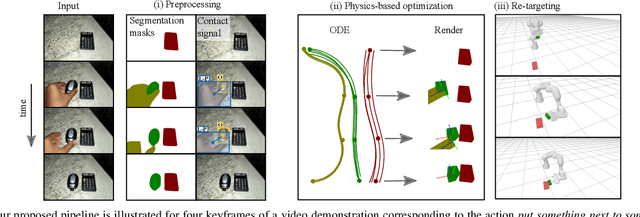


We aim to teach robots to perform simple object manipulation tasks by watching a single video demonstration. Towards this goal, we propose an optimization approach that outputs a coarse and temporally evolving 3D scene to mimic the action demonstrated in the input video. Similar to previous work, a differentiable renderer ensures perceptual fidelity between the 3D scene and the 2D video. Our key novelty lies in the inclusion of a differentiable approach to solve a set of Ordinary Differential Equations (ODEs) that allows us to approximately model laws of physics such as gravity, friction, and hand-object or object-object interactions. This not only enables us to dramatically improve the quality of estimated hand and object states, but also produces physically admissible trajectories that can be directly translated to a robot without the need for costly reinforcement learning. We evaluate our approach on a 3D reconstruction task that consists of 54 video demonstrations sourced from 9 actions such as pull something from right to left or put something in front of something. Our approach improves over previous state-of-the-art by almost 30%, demonstrating superior quality on especially challenging actions involving physical interactions of two objects such as put something onto something. Finally, we showcase the learned skills on a Franka Emika Panda robot.