 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Nash Equilibria in Zero-Sum Markov Games: A Single Time-scale Algorithm Under Weak Reachability
Paper and Code
Dec 13, 2023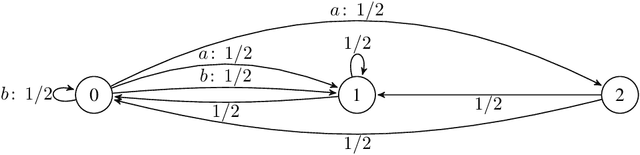

We consider decentralized learning for zero-sum games, where players only see their payoff information and are agnostic to actions and payoffs of the opponent. Previous works demonstrated convergence to a Nash equilibrium in this setting using double time-scale algorithms under strong reachability assumptions. We address the open problem of achieving an approximate Nash equilibrium efficiently with an uncoupled and single time-scale algorithm under weaker conditions. Our contribution is a rational and convergent algorithm, utilizing Tsallis-entropy regularization in a value-iteration-based approach. The algorithm learns an approximate Nash equilibrium in polynomial time, requiring only the existence of a policy pair that induces an irreducible and aperiodic Markov chain, thus considerably weakening past assumptions. Our analysis leverages negative drift inequalities and introduces novel properties of Tsallis entropy that are of independent interest.