 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multivariate CDFs and Copulas using Tensor Factorization
Paper and Code
Oct 13, 2022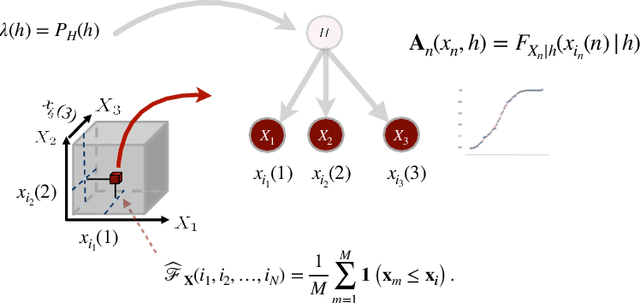
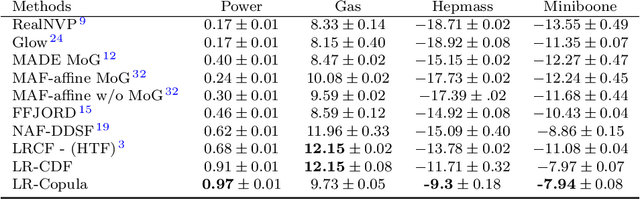
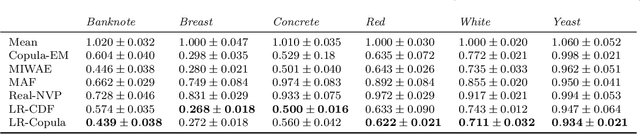
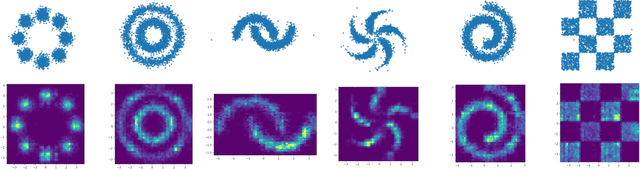
Learning the multivariate distribution of data is a core challenge in statistics and machine learning. Traditional methods aim for the probability density function (PDF) and are limited by the curse of dimensionality. Modern neural methods are mostly based on black-box models, lacking identifiability guarantees. In this work, we aim to learn multivariate cumulative distribution functions (CDFs), as they can handle mixed random variables, allow efficient box probability evaluation, and have the potential to overcome local sample scarcity owing to their cumulative nature. We show that any grid sampled version of a joint CDF of mixed random variables admits a universal representation as a naive Bayes model via the Canonical Polyadic (tensor-rank) decomposition. By introducing a low-rank model, either directly in the raw data domain, or indirectly in a transformed (Copula) domain, the resulting model affords efficient sampling, closed form inference and uncertainty quantification, and comes with uniqueness guarantees under relatively mild conditions. We demonstrate the superior performance of the proposed model in several synthetic and real datasets and applications including regression, sampling and data imputation. Interestingly, our experiments with real data show that it is possible to obtain better density/mass estimates indirectly via a low-rank CDF model, than a low-rank PDF/PMF model.