 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Montezuma's Revenge from a Single Demonstration
Paper and Code
Dec 08, 2018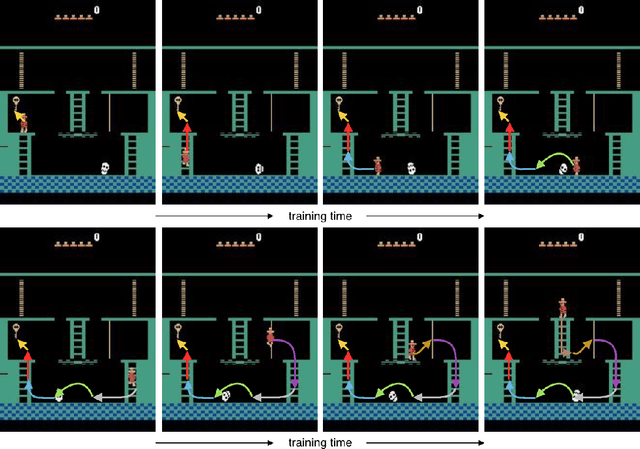
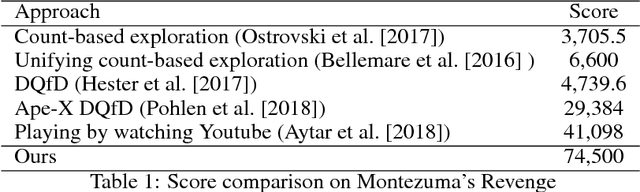
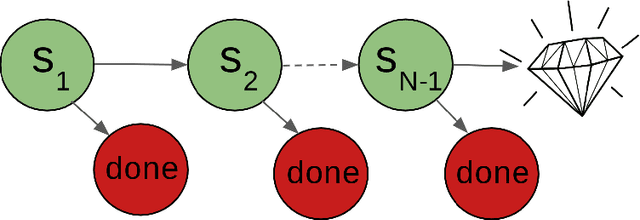
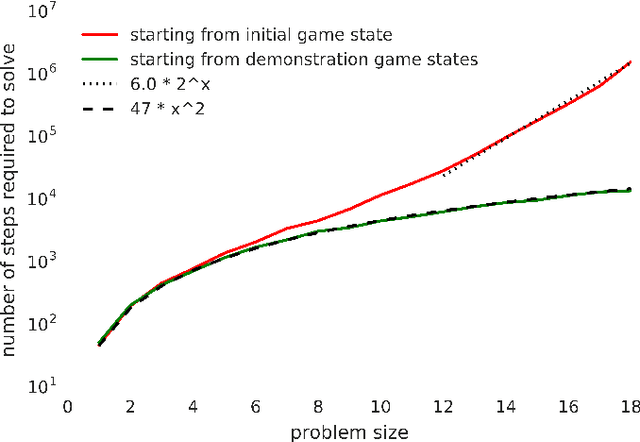
We propose a new method for learning from a single demonstration to solve hard exploration tasks like the Atari game Montezuma's Revenge. Instead of imitating human demonstrations, as proposed in other recent works, our approach is to maximize rewards directly. Our agent is trained using off-the-shelf reinforcement learning, but starts every episode by resetting to a state from a demonstration. By starting from such demonstration states, the agent requires much less exploration to learn a game compared to when it starts from the beginning of the game at every episode. We analyze reinforcement learning for tasks with sparse rewards in a simple toy environment, where we show that the run-time of standard RL methods scales exponentially in the number of states between rewards. Our method reduces this to quadratic scaling, opening up many tasks that were previously infeasible. We then apply our method to Montezuma's Revenge, for which we present a trained agent achieving a high-score of 74,500, better than any previously published result.