 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mixtures of Smooth Product Distributions: Identifiability and Algorithm
Paper and Code
Apr 02, 2019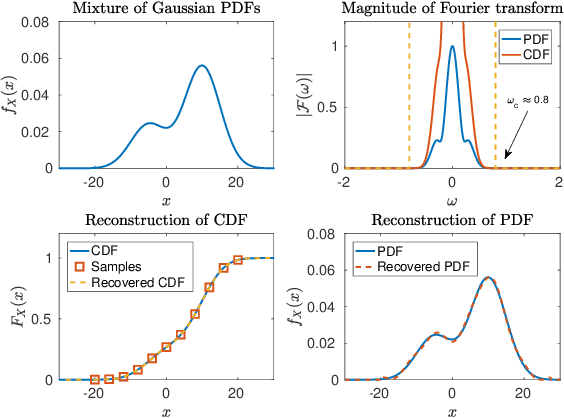
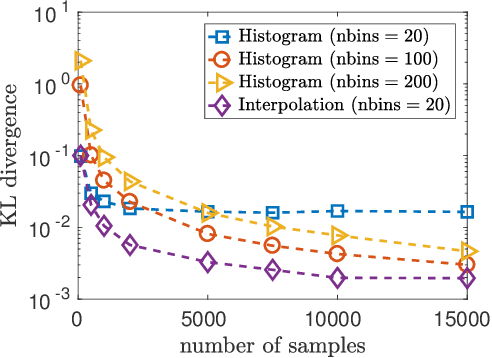
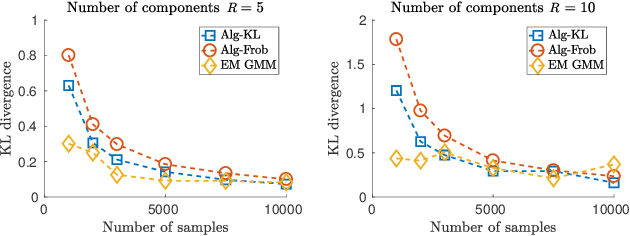
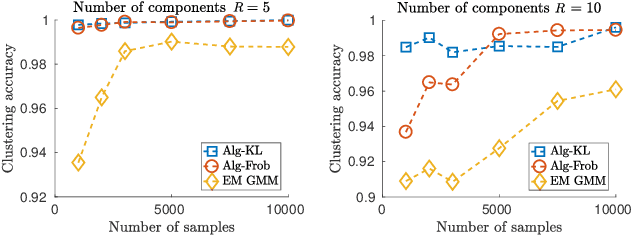
We study the problem of learning a mixture model of non-parametric product distributions. The problem of learning a mixture model is that of finding the component distributions along with the mixing weights using observed samples generated from the mixture. The problem is well-studied in the parametric setting, i.e., when the component distributions are members of a parametric family -- such as Gaussian distributions. In this work, we focus on multivariate mixtures of non-parametric product distributions and propose a two-stage approach which recovers the component distributions of the mixture under a smoothness condition. Our approach builds upon the identifiability properties of the canonical polyadic (low-rank) decomposition of tensors, in tandem with Fourier and Shannon-Nyquist sampling staples from signal processing. We demonstrate the effectiveness of the approach on synthetic and real datasets.