 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mask-aware CLIP Representations for Zero-Shot Segmentation
Paper and Code

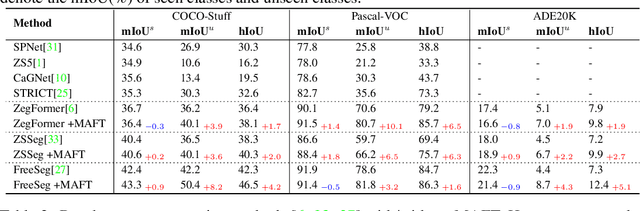
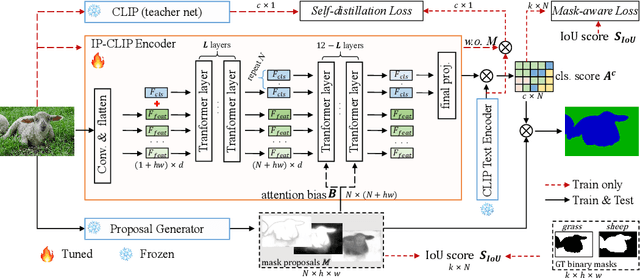
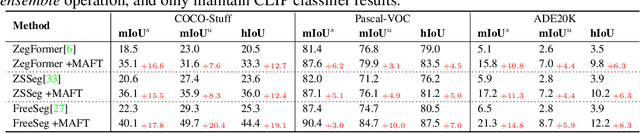
Recently, pre-trained vision-language models have been increasingly used to tackle the challenging zero-shot segmentation task. Typical solutions follow the paradigm of first generating mask proposals and then adopting CLIP to classify them. To maintain the CLIP's zero-shot transferability, previous practices favour to freeze CLIP during training. However, in the paper, we reveal that CLIP is insensitive to different mask proposals and tends to produce similar predictions for various mask proposals of the same image. This insensitivity results in numerous false positives when classifying mask proposals. This issue mainly relates to the fact that CLIP is trained with image-level supervision. To alleviate this issue, we propose a simple yet effective method, named Mask-aware Fine-tuning (MAFT). Specifically, Image-Proposals CLIP Encoder (IP-CLIP Encoder) is proposed to handle arbitrary numbers of image and mask proposals simultaneously. Then, mask-aware loss and self-distillation loss are designed to fine-tune IP-CLIP Encoder, ensuring CLIP is responsive to different mask proposals while not sacrificing transferability. In this way, mask-aware representations can be easily learned to make the true positives stand out. Notably, our solution can seamlessly plug into most existing methods without introducing any new parameters during the fine-tuning process. We conduct extensive experiments on the popular zero-shot benchmarks. With MAFT, the performance of the state-of-the-art methods is promoted by a large margin: 50.4% (+ 8.2%) on COCO, 81.8% (+ 3.2%) on Pascal-VOC, and 8.7% (+4.3%) on ADE20K in terms of mIoU for unseen classes. The code is available at https://github.com/jiaosiyu1999/MAFT.git.