Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Language from a Large (Unannotated) Corpus
Paper and Code
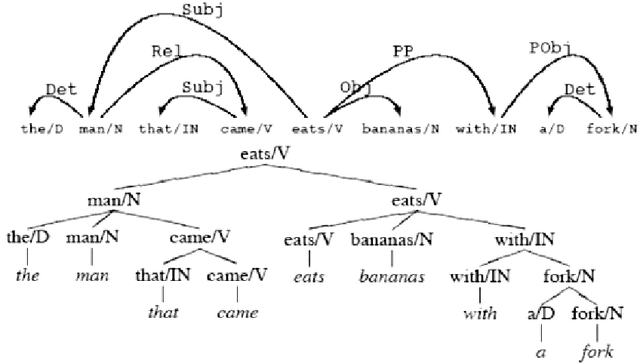
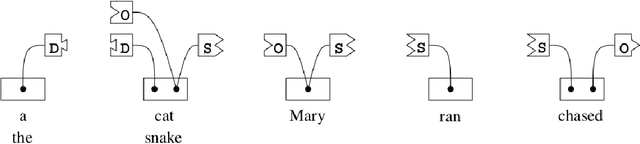
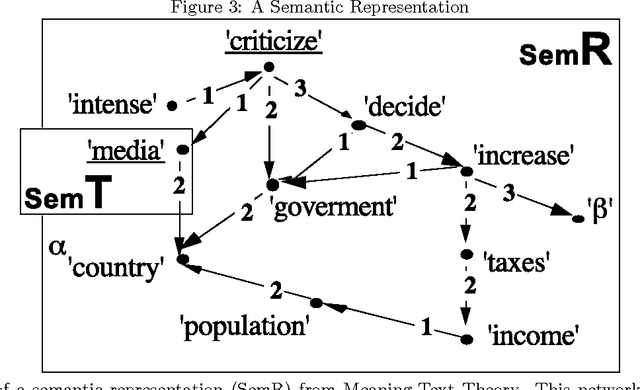
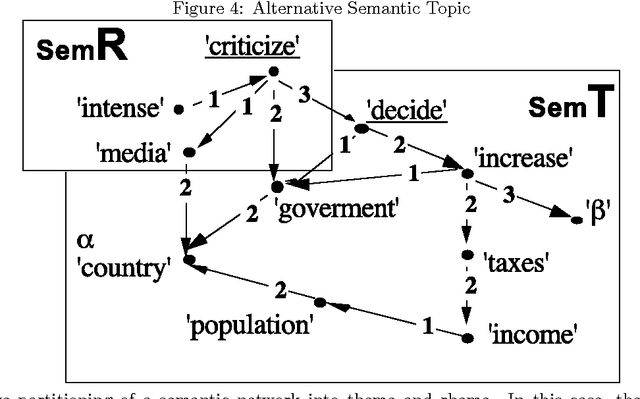
A novel approach to the fully automated, unsupervised extraction of dependency grammars and associated syntax-to-semantic-relationship mappings from large text corpora is described. The suggested approach builds on the authors' prior work with the Link Grammar, RelEx and OpenCog systems, as well as on a number of prior papers and approaches from the statistical language learning literature. If successful, this approach would enable the mining of all the information needed to power a natural language comprehension and generation system, directly from a large, unannotated corpus.
* 29 pages, 5 figures, research proposal
View paper on