 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Input and Recurrent Weight Matrices in Echo State Networks
Paper and Code
Nov 13, 2013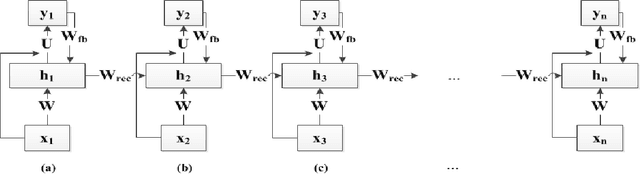
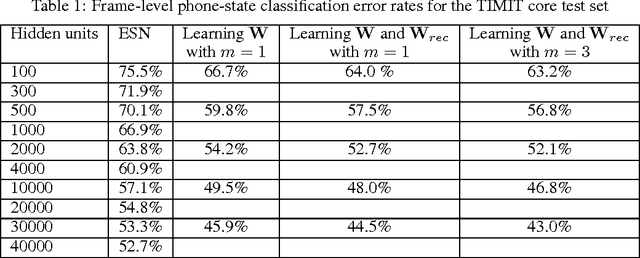

Echo State Networks (ESNs) are a special type of the temporally deep network model, the Recurrent Neural Network (RNN), where the recurrent matrix is carefully designed and both the recurrent and input matrices are fixed. An ESN uses the linearity of the activation function of the output units to simplify the learning of the output matrix. In this paper, we devise a special technique that take advantage of this linearity in the output units of an ESN, to learn the input and recurrent matrices. This has not been done in earlier ESNs due to their well known difficulty in learning those matrices. Compared to the technique of BackPropagation Through Time (BPTT) in learning general RNNs, our proposed method exploits linearity of activation function in the output units to formulate the relationships amongst the various matrices in an RNN. These relationships results in the gradient of the cost function having an analytical form and being more accurate. This would enable us to compute the gradients instead of obtaining them by recursion as in BPTT. Experimental results on phone state classification show that learning one or both the input and recurrent matrices in an ESN yields superior results compared to traditional ESNs that do not learn these matrices, especially when longer time steps are used.