 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Generative Models with the Method of Learned Moments
Paper and Code
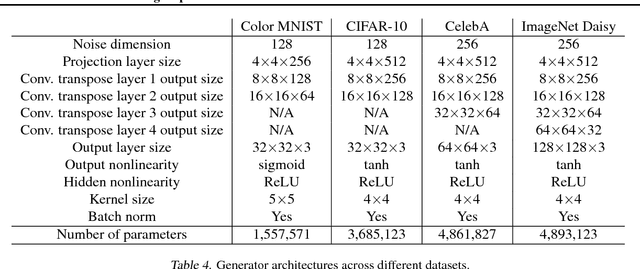
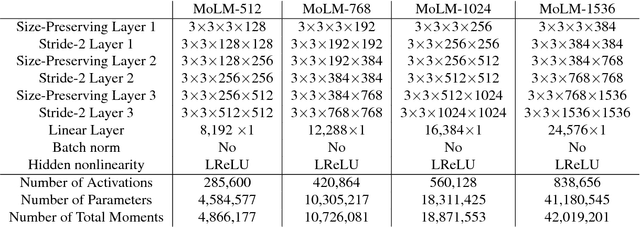

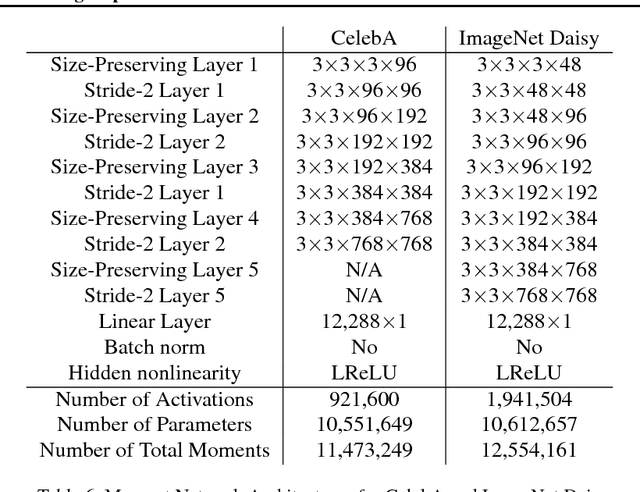
We propose a method of moments (MoM) algorithm for training large-scale implicit generative models. Moment estimation in this setting encounters two problems: it is often difficult to define the millions of moments needed to learn the model parameters, and it is hard to determine which properties are useful when specifying moments. To address the first issue, we introduce a moment network, and define the moments as the network's hidden units and the gradient of the network's output with the respect to its parameters. To tackle the second problem, we use asymptotic theory to highlight desiderata for moments -- namely they should minimize the asymptotic variance of estimated model parameters -- and introduce an objective to learn better moments. The sequence of objectives created by this Method of Learned Moments (MoLM) can train high-quality neural image samplers. On CIFAR-10, we demonstrate that MoLM-trained generators achieve significantly higher Inception Scores and lower Frechet Inception Distances than those trained with gradient penalty-regularized and spectrally-normalized adversarial objectives. These generators also achieve nearly perfect Multi-Scale Structural Similarity Scores on CelebA, and can create high-quality samples of 128x128 images.