 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning high-dimensional probability distributions using tree tensor networks
Paper and Code
Dec 17, 2019
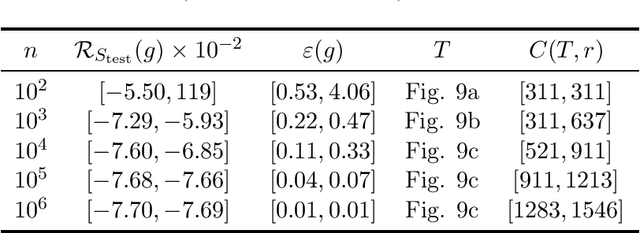
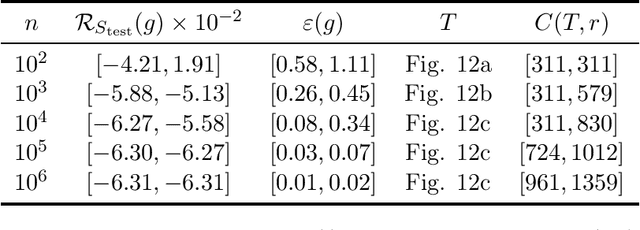
We consider the problem of the estimation of a high-dimensional probability distribution using model classes of functions in tree-based tensor formats, a particular case of tensor networks associated with a dimension partition tree. The distribution is assumed to admit a density with respect to a product measure, possibly discrete for handling the case of discrete random variables. After discussing the representation of classical model classes in tree-based tensor formats, we present learning algorithms based on empirical risk minimization using a $L^2$ contrast. These algorithms exploit the multilinear parametrization of the formats to recast the nonlinear minimization problem into a sequence of empirical risk minimization problems with linear models. A suitable parametrization of the tensor in tree-based tensor format allows to obtain a linear model with orthogonal bases, so that each problem admits an explicit expression of the solution and cross-validation risk estimates. These estimations of the risk enable the model selection, for instance when exploiting sparsity in the coefficients of the representation. A strategy for the adaptation of the tensor format (dimension tree and tree-based ranks) is provided, which allows to discover and exploit some specific structures of high-dimensional probability distributions such as independence or conditional independence. We illustrate the performances of the proposed algorithms for the approximation of classical probabilistic models (such as Gaussian distribution, graphical models, Markov chain).