 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Structures with Differentiable Nondeterministic Stacks
Paper and Code
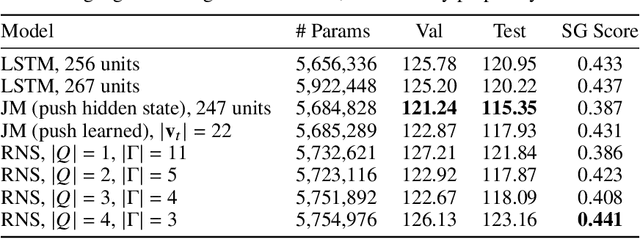
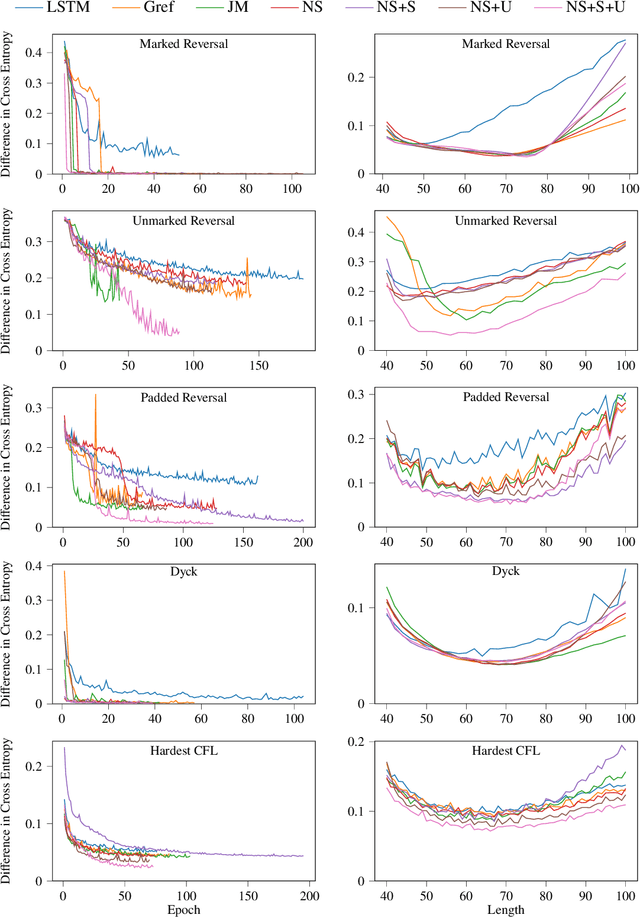
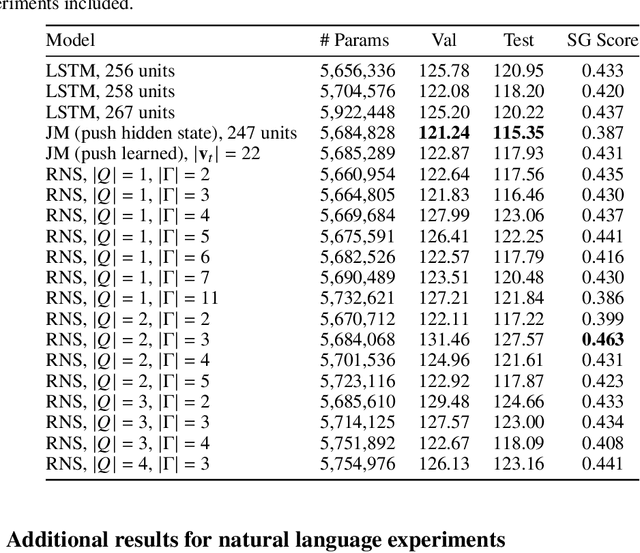

Learning hierarchical structures in sequential data -- from simple algorithmic patterns to natural language -- in a reliable, generalizable way remains a challenging problem for neural language models. Past work has shown that recurrent neural networks (RNNs) struggle to generalize on held-out algorithmic or syntactic patterns without supervision or some inductive bias. To remedy this, many papers have explored augmenting RNNs with various differentiable stacks, by analogy with finite automata and pushdown automata. In this paper, we present a stack RNN model based on the recently proposed Nondeterministic Stack RNN (NS-RNN) that achieves lower cross-entropy than all previous stack RNNs on five context-free language modeling tasks (within 0.05 nats of the information-theoretic lower bound), including a task in which the NS-RNN previously failed to outperform a deterministic stack RNN baseline. Our model assigns arbitrary positive weights instead of probabilities to stack actions, and we provide an analysis of why this improves training. We also propose a restricted version of the NS-RNN that makes it practical to use for language modeling on natural language and present results on the Penn Treebank corpus.