 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generative Models with Goal-conditioned Reinforcement Learning
Paper and Code

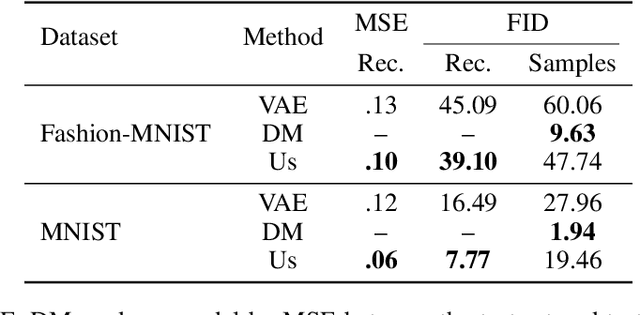


We present a novel, alternative framework for learning generative models with goal-conditioned reinforcement learning. We define two agents, a goal conditioned agent (GC-agent) and a supervised agent (S-agent). Given a user-input initial state, the GC-agent learns to reconstruct the training set. In this context, elements in the training set are the goals. During training, the S-agent learns to imitate the GC-agent while remaining agnostic of the goals. At inference we generate new samples with the S-agent. Following a similar route as in variational auto-encoders, we derive an upper bound on the negative log-likelihood that consists of a reconstruction term and a divergence between the GC-agent policy and the (goal-agnostic) S-agent policy. We empirically demonstrate that our method is able to generate diverse and high quality samples in the task of image synthesis.