 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalized Medical Image Representations through Image-Graph Contrastive Pretraining
Paper and Code
May 15, 2024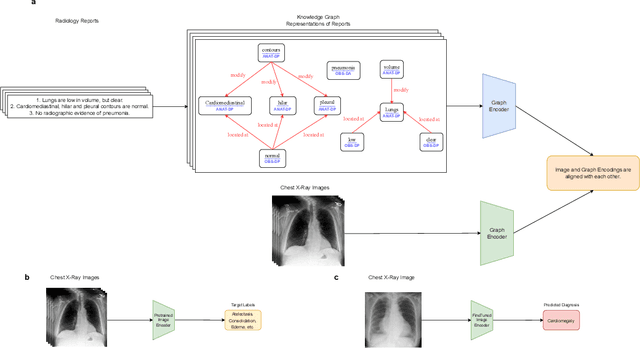
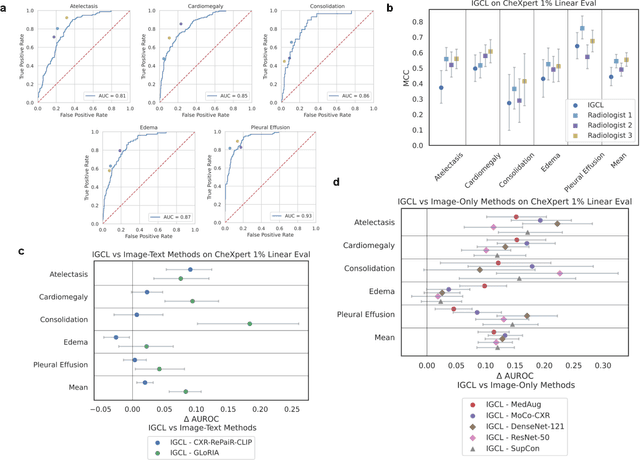
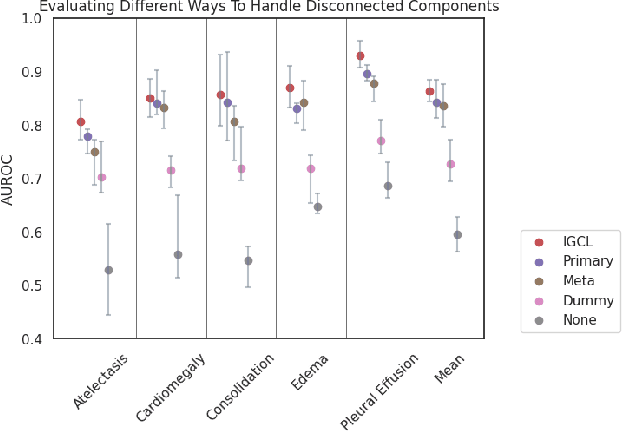

Medical image interpretation using deep learning has shown promise but often requires extensive expert-annotated datasets. To reduce this annotation burden, we develop an Image-Graph Contrastive Learning framework that pairs chest X-rays with structured report knowledge graphs automatically extracted from radiology notes. Our approach uniquely encodes the disconnected graph components via a relational graph convolution network and transformer attention. In experiments on the CheXpert dataset, this novel graph encoding strategy enabled the framework to outperform existing methods that use image-text contrastive learning in 1% linear evaluation and few-shot settings, while achieving comparable performance to radiologists. By exploiting unlabeled paired images and text, our framework demonstrates the potential of structured clinical insights to enhance contrastive learning for medical images. This work points toward reducing demands on medical experts for annotations, improving diagnostic precision, and advancing patient care through robust medical image understanding.