 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Positive and Unlabeled Data by Identifying the Annotation Process
Paper and Code
Mar 02, 2020
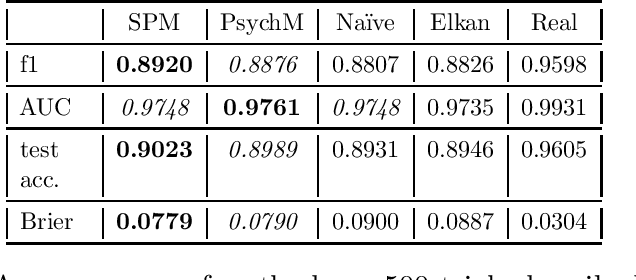


In binary classification, Learning from Positive and Unlabeled data (LePU) is semi-supervised learning but with labeled elements from only one class. Most of the research on LePU relies on some form of independence between the selection process of annotated examples and the features of the annotated class, known as the Selected Completely At Random (SCAR) assumption. Yet the annotation process is an important part of the data collection, and in many cases it naturally depends on certain features of the data (e.g., the intensity of an image and the size of the object to be detected in the image). Without any constraints on the model for the annotation process, classification results in the LePU problem will be highly non-unique. So proper, flexible constraints are needed. In this work we incorporate more flexible and realistic models for the annotation process than SCAR, and more importantly, offer a solution for the challenging LePU problem. On the theory side, we establish the identifiability of the properties of the annotation process and the classification function, in light of the considered constraints on the data-generating process. We also propose an inference algorithm to learn the parameters of the model, with successful experimental results on both simulated and real data. We also propose a novel real-world dataset forLePU, as a benchmark dataset for future studies.