 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Learners: Adapting Reinforcement Learning Agents to be Competitive in a Card Game
Paper and Code

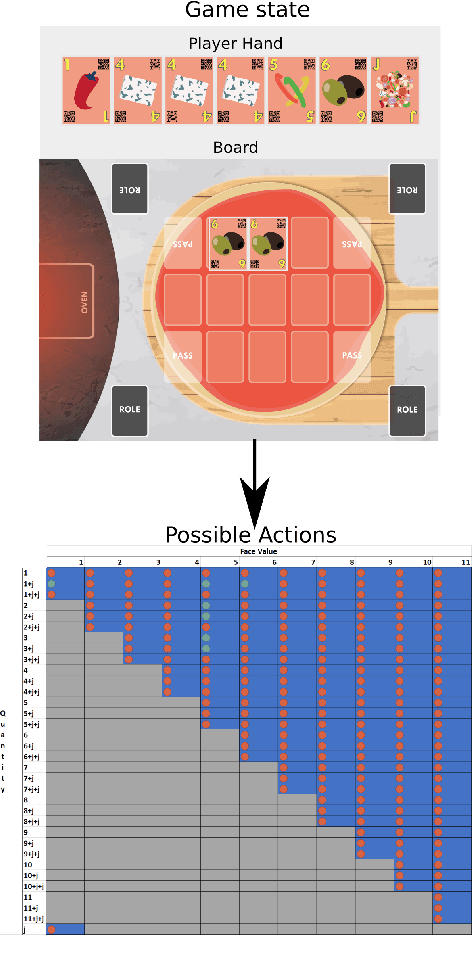
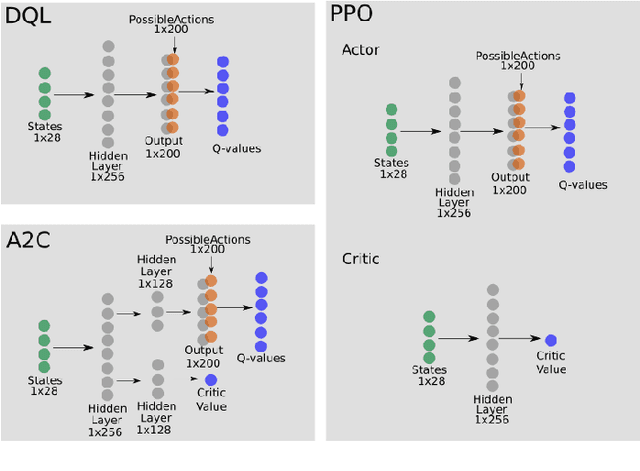
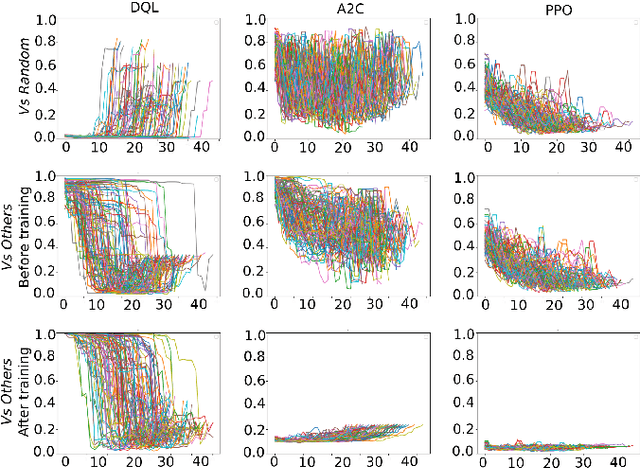
Learning how to adapt to complex and dynamic environments is one of the most important factors that contribute to our intelligence. Endowing artificial agents with this ability is not a simple task, particularly in competitive scenarios. In this paper, we present a broad study on how popular reinforcement learning algorithms can be adapted and implemented to learn and to play a real-world implementation of a competitive multiplayer card game. We propose specific training and validation routines for the learning agents, in order to evaluate how the agents learn to be competitive and explain how they adapt to each others' playing style. Finally, we pinpoint how the behavior of each agent derives from their learning style and create a baseline for future research on this scenario.