 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Demonstrations using Signal Temporal Logic
Paper and Code
Feb 15, 2021
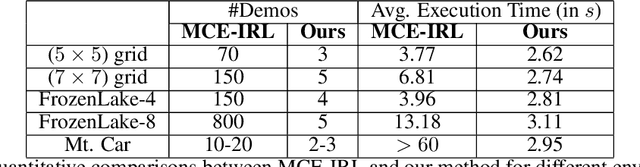
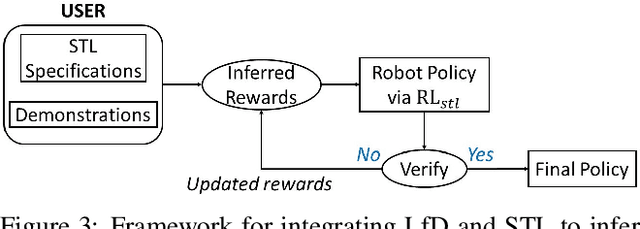

Learning-from-demonstrations is an emerging paradigm to obtain effective robot control policies for complex tasks via reinforcement learning without the need to explicitly design reward functions. However, it is susceptible to imperfections in demonstrations and also raises concerns of safety and interpretability in the learned control policies. To address these issues, we use Signal Temporal Logic to evaluate and rank the quality of demonstrations. Temporal logic-based specifications allow us to create non-Markovian rewards, and also define interesting causal dependencies between tasks such as sequential task specifications. We validate our approach through experiments on discrete-world and OpenAI Gym environments, and show that our approach outperforms the state-of-the-art Maximum Causal Entropy Inverse Reinforcement Learning.