 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from both experts and data
Paper and Code
Oct 29, 2019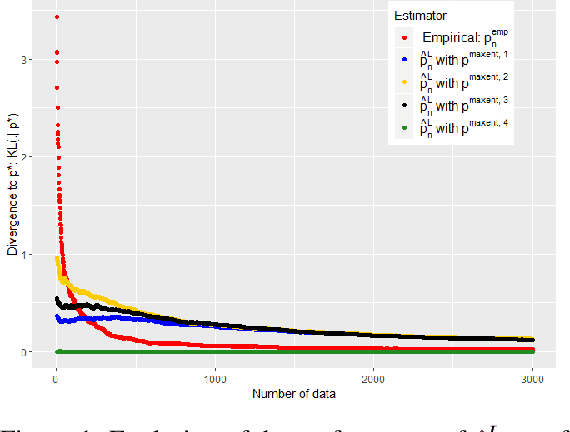
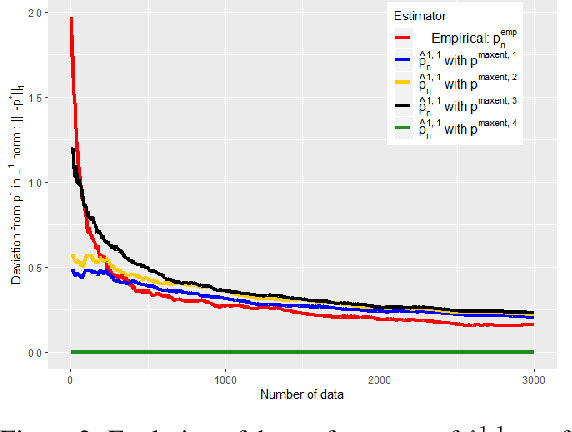
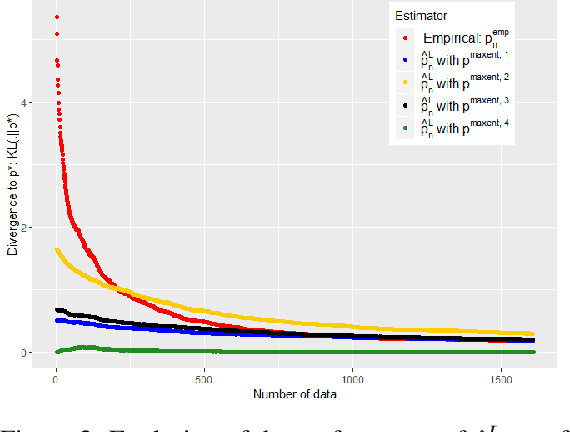

In this work we study the problem of inferring a discrete probability distribution using both expert knowledge and empirical data. This is an important issue for many applications where the scarcity of data prevents a purely empirical approach. In this context, it is common to rely first on an initial domain knowledge a priori before proceeding to an online data acquisition. We are particularly interested in the intermediate regime where we do not have enough data to do without the initial expert a priori of the experts, but enough to correct it if necessary. We present here a novel way to tackle this issue with a method providing an objective way to choose the weight to be given to experts compared to data. We show, both empirically and theoretically, that our proposed estimator is always more efficient than the best of the two models (expert or data) within a constant.