 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dual-Fused Modality-Aware Representations for RGBD Tracking
Paper and Code


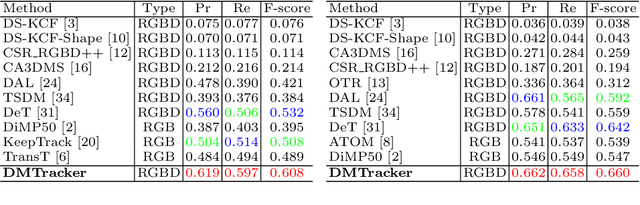

With the development of depth sensors in recent years, RGBD object tracking has received significant attention. Compared with the traditional RGB object tracking, the addition of the depth modality can effectively solve the target and background interference. However, some existing RGBD trackers use the two modalities separately and thus some particularly useful shared information between them is ignored. On the other hand, some methods attempt to fuse the two modalities by treating them equally, resulting in the missing of modality-specific features. To tackle these limitations, we propose a novel Dual-fused Modality-aware Tracker (termed DMTracker) which aims to learn informative and discriminative representations of the target objects for robust RGBD tracking. The first fusion module focuses on extracting the shared information between modalities based on cross-modal attention. The second aims at integrating the RGB-specific and depth-specific information to enhance the fused features. By fusing both the modality-shared and modality-specific information in a modality-aware scheme, our DMTracker can learn discriminative representations in complex tracking scenes. Experiments show that our proposed tracker achieves very promising results on challenging RGBD benchmarks.