 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dense Rewards for Contact-Rich Manipulation Tasks
Paper and Code
Nov 17, 2020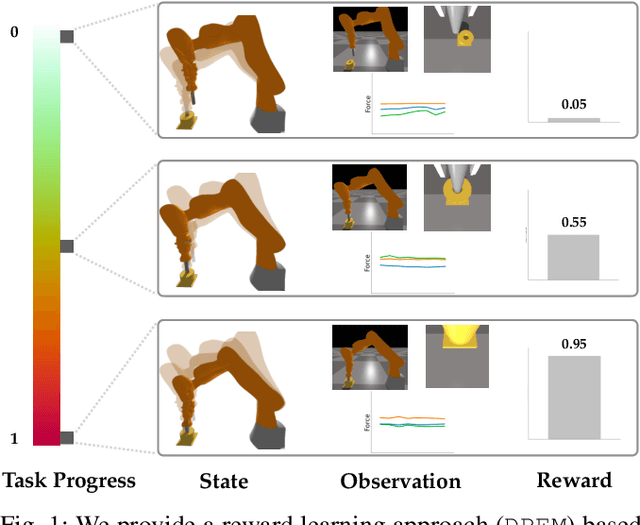
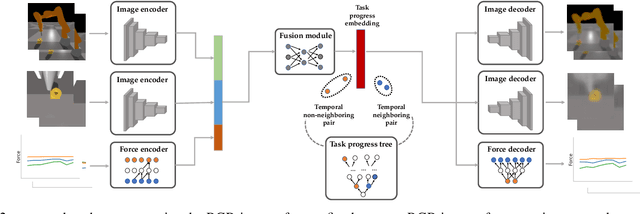
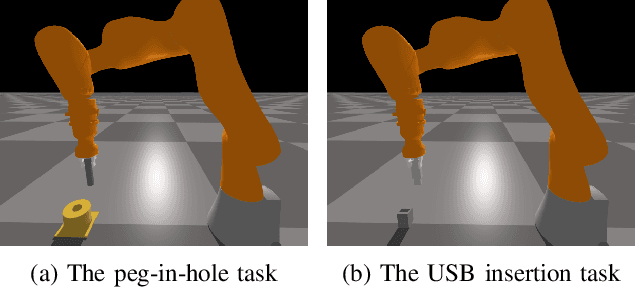

Rewards play a crucial role in reinforcement learning. To arrive at the desired policy, the design of a suitable reward function often requires significant domain expertise as well as trial-and-error. Here, we aim to minimize the effort involved in designing reward functions for contact-rich manipulation tasks. In particular, we provide an approach capable of extracting dense reward functions algorithmically from robots' high-dimensional observations, such as images and tactile feedback. In contrast to state-of-the-art high-dimensional reward learning methodologies, our approach does not leverage adversarial training, and is thus less prone to the associated training instabilities. Instead, our approach learns rewards by estimating task progress in a self-supervised manner. We demonstrate the effectiveness and efficiency of our approach on two contact-rich manipulation tasks, namely, peg-in-hole and USB insertion. The experimental results indicate that the policies trained with the learned reward function achieves better performance and faster convergence compared to the baselines.