 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning camera viewpoint using CNN to improve 3D body pose estimation
Paper and Code
Sep 18, 2016
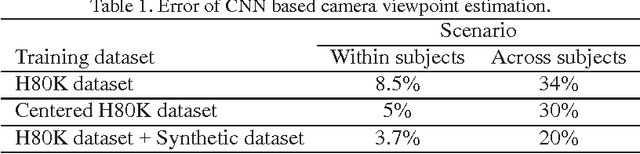
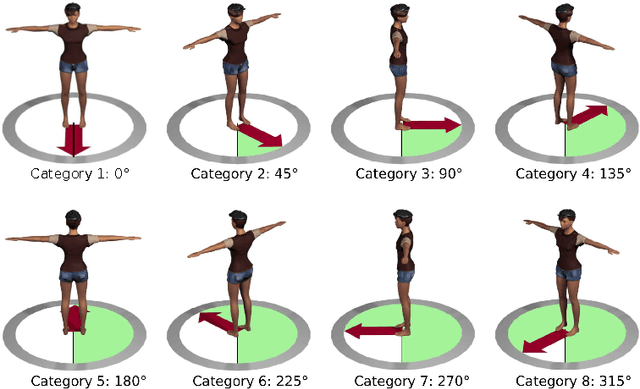

The objective of this work is to estimate 3D human pose from a single RGB image. Extracting image representations which incorporate both spatial relation of body parts and their relative depth plays an essential role in accurate3D pose reconstruction. In this paper, for the first time, we show that camera viewpoint in combination to 2D joint lo-cations significantly improves 3D pose accuracy without the explicit use of perspective geometry mathematical models.To this end, we train a deep Convolutional Neural Net-work (CNN) to learn categorical camera viewpoint. To make the network robust against clothing and body shape of the subject in the image, we utilized 3D computer rendering to synthesize additional training images. We test our framework on the largest 3D pose estimation bench-mark, Human3.6m, and achieve up to 20% error reduction compared to the state-of-the-art approaches that do not use body part segmentation.