 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Semantic Similarity Makes Abstractive Summarization Better
Paper and Code
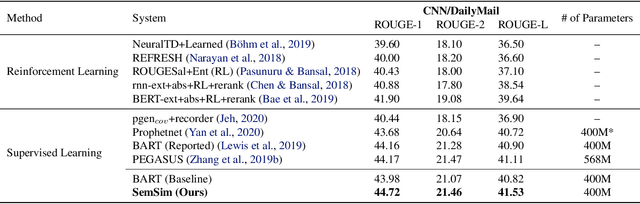
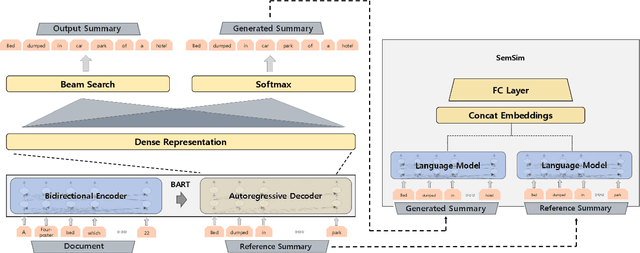


One of the obstacles of abstractive summarization is the presence of various potentially correct predictions. Widely used objective functions for supervised learning, such as cross-entropy loss, cannot handle alternative answers effectively. Rather, they act as a training noise. In this paper, we propose Semantic Similarity strategy that can consider semantic meanings of generated summaries while training. Our training objective includes maximizing semantic similarity score which is calculated by an additional layer that estimates semantic similarity between generated summary and reference summary. By leveraging pre-trained language models, our model achieves a new state-of-the-art performance, ROUGE-L score of 41.5 on CNN/DM dataset. To support automatic evaluation, we also conducted human evaluation and received higher scores relative to both baseline and reference summaries.